![]()
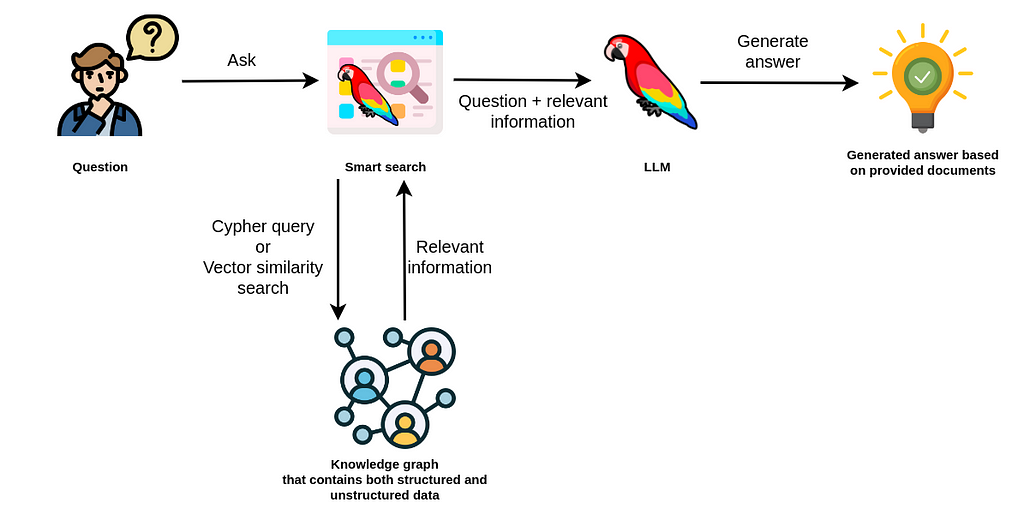
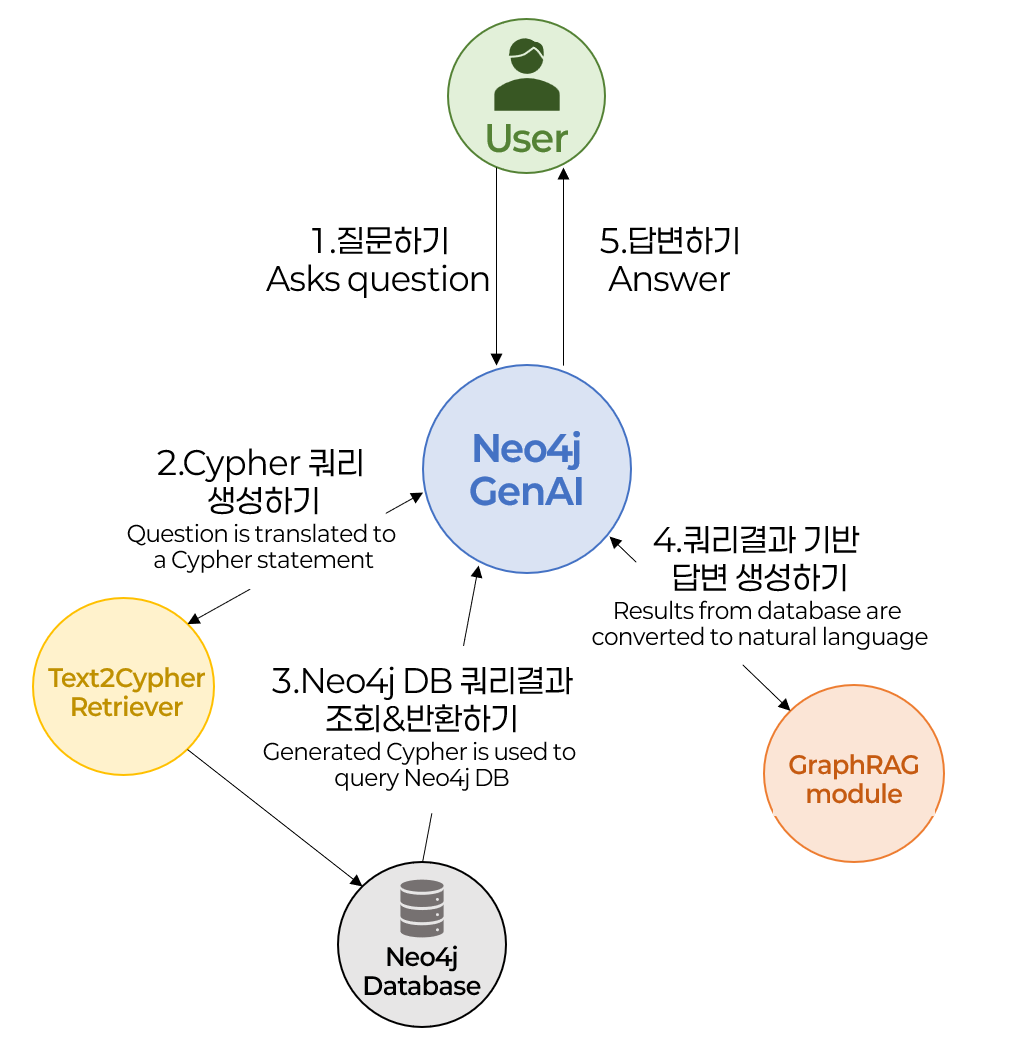
Knowledge Graph Knowledge Graph(지식 그래프)는 semantic network 라고도 알려져 있으며, 사물, 사건, 상황, 개념 등의 현실세계에서 다루어 지는 다양한 엔티티(Entity)들을 그들 간의 관계성(Relationship)과 함께 표현하는 그래프입니다. Knowledge Graph는 꽤 오래전부터 등장한 개념이지만, 최근 RAG(Retrieval-Augmented Generation) 방식으로 LLM(Large Language Model)을 사용하는 사례가 늘어나면서 지식 베이스 구조화의 중요성이 더욱 증대되고 있습니다. 특히 Graph 기반의 지식 저장 방식은 LLM 성능향상에 도움을 준다고 알려져 있습니다. GraphDB를 활용하면, 정보 간의 복잡한 관계를 구조화..
![]()
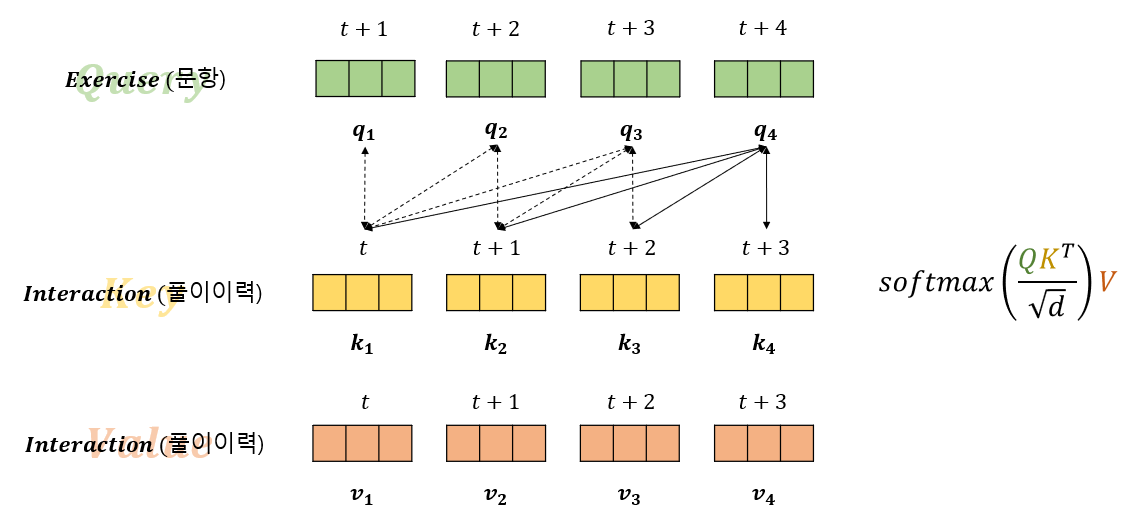
Last Query Transformer RNN for knowledge tracing 🚩 https://www.kaggle.com/competitions/riiid-test-answer-prediction Riiid Answer Correctness Prediction | Kaggle www.kaggle.com 2020년, 산타토익을 개발한 뤼이드는 Kaggle을 통해 정오답 예측 대회 (Answer Correctness Prediction) 를 개최했습니다. 제가 리뷰한 모델은 본 대회에서 리더보드 1위를 차지한 모델로, Last Query Transformer RNN for knowledge tracing 입니다. 해당 모델의 전체적인 구조를 중심으로, 정오답을 예측하기까지의 과정을 따라가보려..
![]()
지식추적에 적용한 셀프 어텐션(Self Attention) Transformer가 등장하면서 셀프 어텐션(Self Attention)은 시퀀스 데이터를 처리하기 위한 필수적 요소로 사용되고 있는데요. 대표적으로 문장과 같은 자연어가 이에 해당합니다. 지식 추적 (Knowledge Tracing) 에서도 학생의 풀이 이력이라는 시퀀스 데이터를 다루게 됩니다. 그렇기 때문에 이 셀프 어텐션을 지식추적에 활용한 모델 구조가 연구되었고, 그 중 "A Self-Attentive model for Knowledge Tracing(SAKT)" 논문이 대표적입니다. 본 글에서는 SAKT를 통해 지식추적에 셀프어텐션을 어떻게 적용했는 지 상세히 살펴보고, 파이토치 코드를 통해서도 이해하고자 합니다. A Self-..
![]()
Factorization Machines : https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf 1. Factorization Machines 오늘 다루어볼 추천모델은 Factorization Machines(이하 FM)입니다. FM은 Factorized 파라미터를 사용하여 변수간 interaction을 구한다는 것이 특징인데요, 따라서 sparse한 행렬 데이터인 경우에도 잘 적용할 수 있다는 것이 특징이자 장점입니다. FM 논문에서는 적용예시로 영화 평점 예측 모델을 제시하고 있습니다. 위 그림처럼 각 행(row)마다 사용자별 시청 영화, 영화 평점, 시간, 지난 시청 영화를 행렬로 표현하고, 각 행에 대한 target값을 1에서 5사이의 평점으..
![]()
교육분야에서의 AI는 Knowledge Tracing를 통해 적용될 수 있습니다. 그 중 Sequential Data를 사용하여 시간의 흐름에 따라 변화하는 지식 수준을 모델링한 Deep Knowledge Tracing을 살펴보겠습니다. (본 게시글은 Deep Knowledge Tracing(2015) https://papers.nips.cc/paper/2015/hash/bac9162b47c56fc8a4d2a519803d51b3-Abstract.html 을 기반으로 비전공자도 이해할 수 있도록 매우 쉽게 풀어 작성하였습니다.) 1. Knowledge Tracing Knowledge Tracing(지식 추적)이란 학생(user)의 풀이이력을 바탕으로 아직 풀이하지 않은 미래의 문제에 대해 학생의 수행결..
![]()
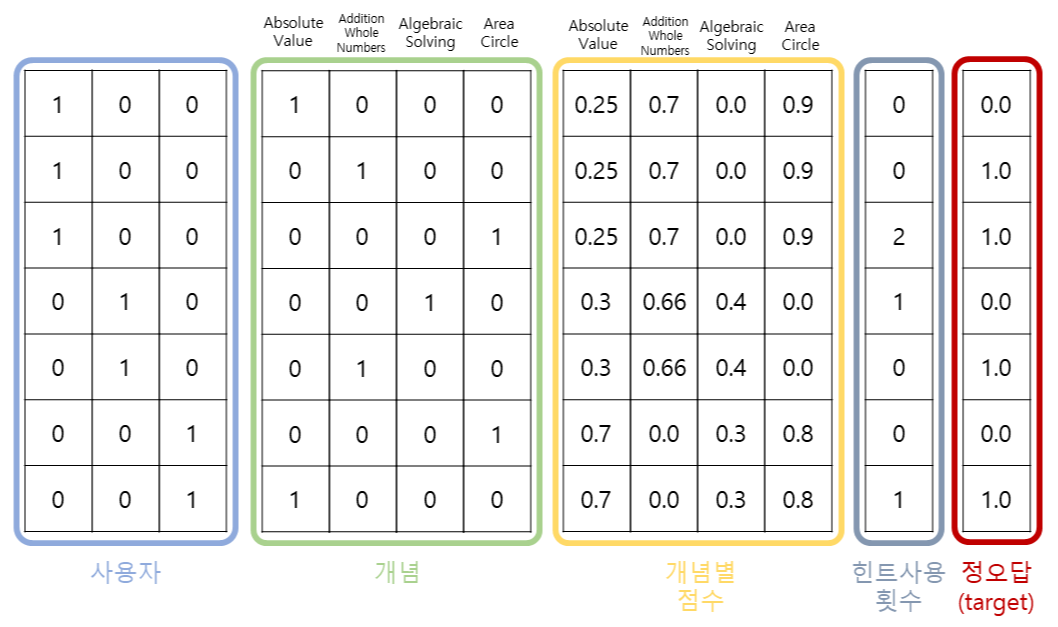
추천시스템의 가장 기본인 협업필터링을 활용하여 교육분야에서 어떻게 활용될 수 있을 지 고민하는 시간을 가져보았습니다. 사용한 데이터는 ASSISTment 2009 데이터로, 학생별 문항 풀이이력이 존재합니다. 데이터에 대한 자세한 설명은 https://uoahvu.tistory.com/entry/AIEd를-위한-학습풀이이력-공개데이터셋 을 참고해주세요. 1. 협업필터링을 통해 특정 학습개념과 유사한 학습개념 찾기 먼저, ASSISTment 2009 데이터는 사용자별 문항 풀이이력이 존재합니다. 위 데이터 예시에서 확인할 수 있듯 해당 데이터를 통해 각 문항이 포함하는 Skill(학습 개념) 이 무엇인지, 그 문항을 맞혔는지 틀렸는 지를 확인할 수 있습니다. (맞힘 : 1 / 틀림 : 0) 보통 협업필터..
![]()
교육분야에서 인공지능을 활용하기 위해서는 가장 기본적이고 대표적으로 데이터셋이 필요합니다. 그래서 공개된 학습이력 데이터셋 5가지 정도를 공유하고자 합니다. 1. ASSISTment 2009-2010 datasets 가장 먼저, ASSISTment 2009-2010 데이터셋으로 일반적으로 Knowledge Tracing 모델 성능검증을 위해 가장 많이 사용되는 데이터 셋입니다. 해당데이터 셋은 skill_builder 와 non_skill_builder 타입 두가지로 나뉘어져 있으며, 이 중 특정 개념을 마스터 한 것으로 간주 될때는 더이상 문제를 출제하지 않았다는 skill_builder 데이터셋을 기준으로 작성하였습니다. 아래 링크에서 데이터셋을 다운로드 받을 수 있습니다. https://sites..