
추천시스템의 가장 기본인 협업필터링을 활용하여 교육분야에서 어떻게 활용될 수 있을 지 고민하는 시간을 가져보았습니다. 사용한 데이터는 ASSISTment 2009 데이터로, 학생별 문항 풀이이력이 존재합니다.
데이터에 대한 자세한 설명은 https://uoahvu.tistory.com/entry/AIEd를-위한-학습풀이이력-공개데이터셋 을 참고해주세요.
1. 협업필터링을 통해 특정 학습개념과 유사한 학습개념 찾기
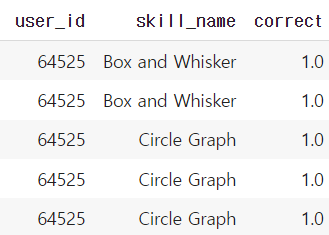
먼저, ASSISTment 2009 데이터는 사용자별 문항 풀이이력이 존재합니다. 위 데이터 예시에서 확인할 수 있듯 해당 데이터를 통해 각 문항이 포함하는 Skill(학습 개념) 이 무엇인지, 그 문항을 맞혔는지 틀렸는 지를 확인할 수 있습니다. (맞힘 : 1 / 틀림 : 0) 보통 협업필터링은 사용자가 매긴 평점 데이터 등을 통해 사용자의 취향을 파악하기 위해 활용됩니다. 그래서 사용자들에게서 유사한 평점을 받은 컨텐츠 쌍을 유사하다고 파악하여, 특정 컨텐츠에 대해 좋은 평점을 매긴 사용자에게 그 컨텐츠와 유사도가 높은 컨텐츠들을 추천하는 방식으로 활용되고 있습니다.
그런데 문항풀이이력에서는 사용자들의 취향이라고 할만한 것들은 없습니다. 그래서 먼저, 학습 개념별 사용자들의 점수를 통해 높은 점수를 가지는 것을 강한 개념이라 하고 특정 개념에 강하다면 또 어떤 개념에 강하다고 할 수 있을 지를 파악하는 시스템을 생각해보았습니다.
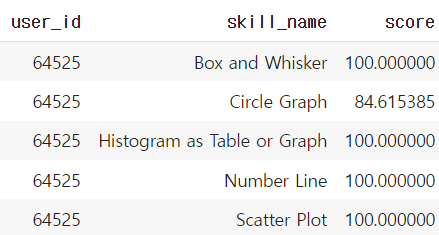
적용을 위해 사용자별 개념별 점수를 계산하여 새로운 데이터프레임으로 전처리 해줍니다. 단순히 개념별 문항개수 대비 맞힌 문항 개수를 계산하여 백분율로 적용해주었습니다. 추가로, 사용자들은 모든 개념에 대한 이력이 없을 수 있기 때문에 풀이하지 않은 개념에 대한 점수는 그냥 0.0 으로 처리해주었습니다. 이는 0점인 학생과 같은 수준으로 만드는 것이기 때문에 이 둘을 구분하여 더 좋은 성능을 낼 수 있다면 고려하여 추후에 적용해보겠습니다.
skill_user_scoring = processed_df.pivot_table('score', index = 'skill_name', columns = 'user_id')
이제 그 데이터프레임에 대해 pivot_table 함수를 적용해주었습니다. 해당 함수를 통해 인덱스와 컬럼을 정해, Skill-user에 따른 점수를 표현해줍니다.
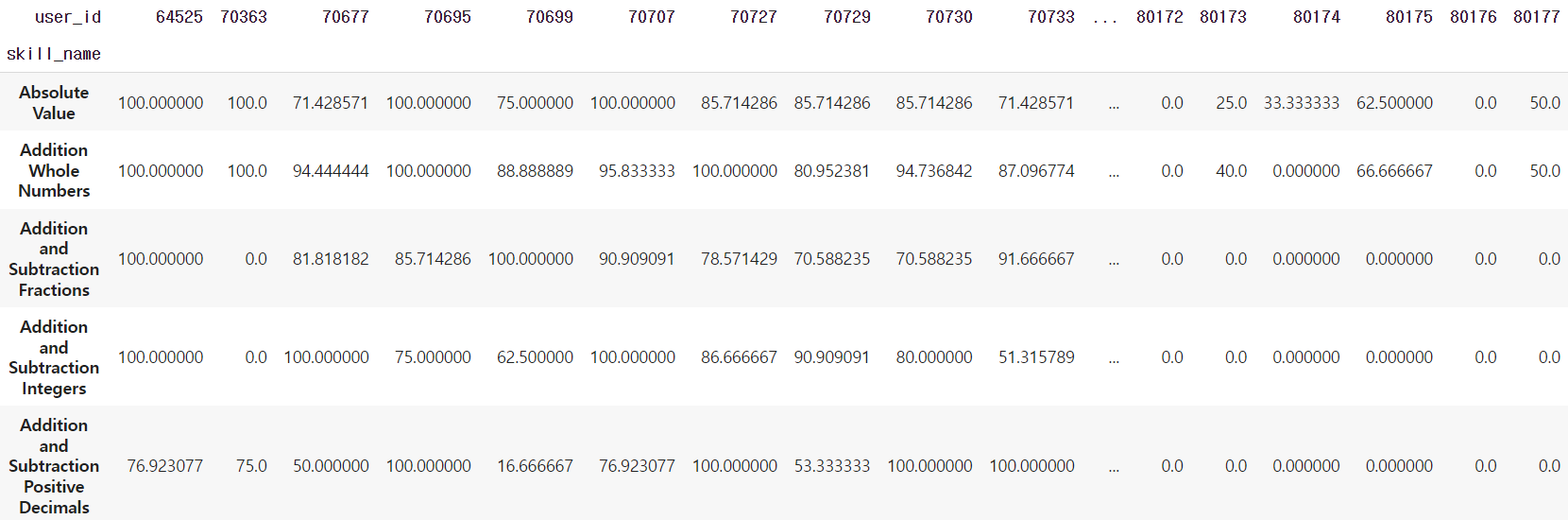
이제 이 테이블을 가지고, skill 간의 유사도를 구해보겠습니다.
from sklearn.metrics.pairwise import cosine_similarity
item_based_similarity = cosine_similarity(skill_user_scoring)
코사인 유사도를 활용했으며, sklearn에서 제공하는 cosine_similarity를 사용합니다.
item_based_similarity = pd.DataFrame(data = item_based_similarity, index = skill_user_scoring.index, columns = skill_user_scoring.index)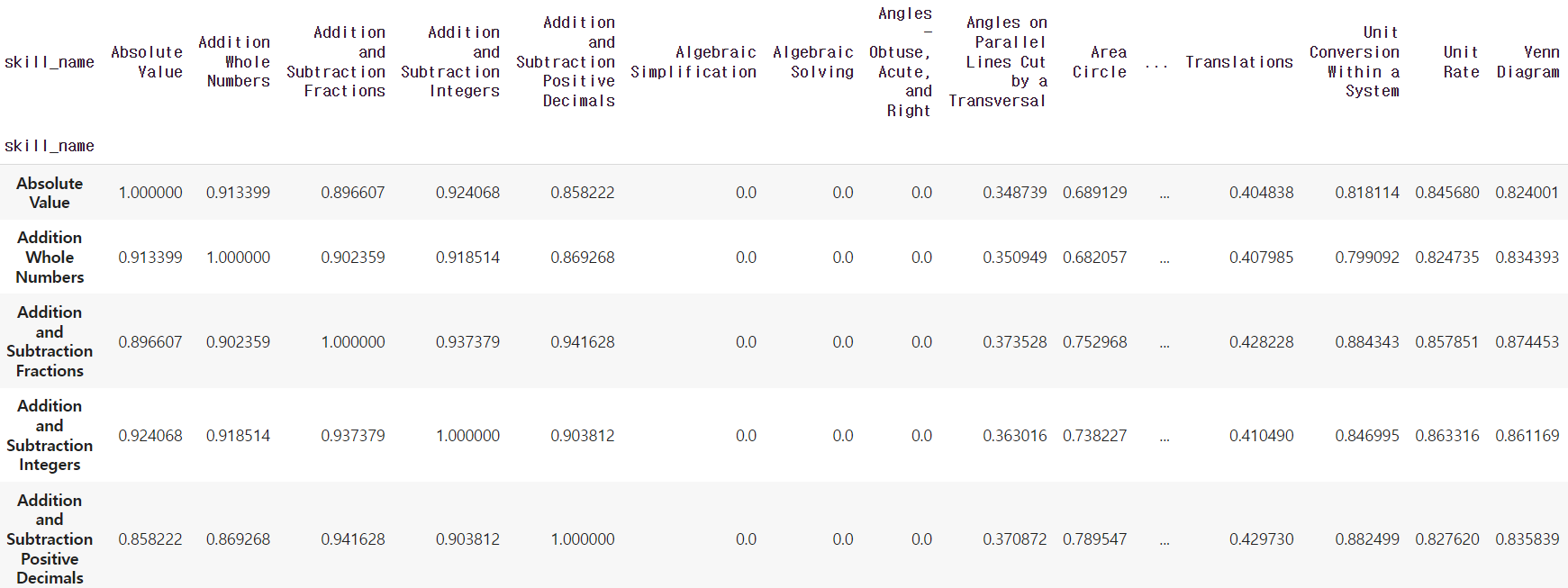
결과를 확인하니, 자기 자신에 대한 유사도는 1.0로 표현된 것을 확인할 수 있었습니다. 이제 이 유사도를 통해 특정 개념과 높은 유사도를 가지는 개념을 파악하기만 하면 끝입니다!
몇가지 학습개념을 직접 인퍼런스 해보았는데요. 참고로, 해당 데이터에 등장하는 개념들은 미국 수학교육과정의 단원들입니다.

<Addition and Subtraction Positive Decimals> 은 양수의 덧셈과 뺄셈입니다. 이와 유사한 개념으로 감지된 것들을 출력해보니 <Addition and Subtraction Fractions> : 분수의 덧셈과 뺄셈, <Addition and Subtraction Integers> : 정수의 덧셈과 뺄셈, <Order of Operations +,-,/,* () positive reals> : 양의 실수 연산 순서 등이 도출되었네요. 양수의 덧셈과 뺄셈을 잘하는 학생들은 해당 단원들에도 강함을 파악할 수 있었습니다. 실제로도 그럴 것 같은 개념들이 도출되어 신기하네요!

<Volume Cylinder> : 원기둥의 부피에 강한 학생들은 <Volume Sphere> : 구의 부피, <Volume Rectangular Prism> : 직각기둥의 부피, <Area trapezoid> : 사다리꼴의 면적 등, 실제로 도형과 관련한 개념들이 다수 도출됨을 확인할 수 있었습니다.
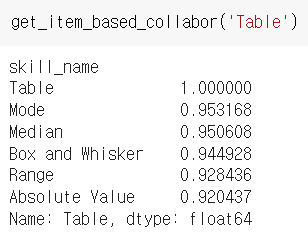
<Table> : 표 개념과 유사한 개념들은 <Mode> : 최빈값, <Median> : 중앙값, <Box and Whisker> : 박스플롯 그래프, <Range> : 범위 등 실제로 표를 통해 대표적으로 얻을 수 있는 인사이트가 포함된 개념들이 나왔습니다. 랜덤으로 몇가지를 인퍼런스 해보았는데 정말 다 직관적으로 연관성이 있는 개념들이 도출되어 신기했습니다.
반대로 특정 개념과 유사하지 않은 개념들을 뽑아보고, 그 특정 개념에 강할 때 반대로 사용자에게 약하거나 낯선 개념들을 풀어보라고 추천하는 알고리즘을 CF를 통해 구현해볼 수도 있겠다는 생각을 할 수 있었습니다!
2. 협업필터링을 통해 특정 학생와 유사한 학생 찾기
첫번째로는 학습 개념간, 즉 item-based CF 였습니다. 또 다른 CF인 user-based CF는 어떻게 활용할 수 있을지를 생각해보았고 이번에는 사용자들의 학습개념별 점수들을 통해 특정 사용자와 다른 사용자들간의 개념별 점수 유사도를 구해 유사한 수준의 사용자들을 감지해낼 수 있을 지를 확인해보겠습니다.
user_skill_scoring = processed_df.pivot_table('score', index = 'user_id', columns = 'skill_name')
이번에는 사용자를 인덱스에 두고 pivot_table을 만들어, 사용자에 대한 유사도를 구하기 위한 준비를 합니다.
from sklearn.metrics.pairwise import cosine_similarity
user_based_similarity = cosine_similarity(user_skill_scoring)user_based_similarity = pd.DataFrame(data = user_based_similarity, index = user_skill_scoring.index, columns = user_skill_scoring.index)

사용자간의 학습개념 점수를 통해 구해본 유사도 계산 결과입니다.

이처럼 사용자가 풀이한 개념별 점수에 따라 강하거나 약한 개념에 대한 수준이 유사한 사용자(코사인 유사도 기반)를 감지해보고, 이를 통해 유사한 사용자들은 어떤 문제들을 많이 틀렸는지, 어떤 개념에 강한지 등을 다양하게 파악해볼 수 있을 듯 합니다.
'AI' 카테고리의 다른 글
| Prompt Engineering 은 어떻게 하는걸까? : ChatGPT 활용 예제와 함께 완벽히 정리하기 (기본편) (1) | 2023.06.18 |
|---|---|
| Matrix Factorization : 개요와 원리부터, 최적화(SGD, ALS)까지 이해하기 (0) | 2023.06.01 |
| FM(Factorization Machines)을 활용한 학생별 문항 맞힐확률 예측하기 (0) | 2023.02.26 |
| 시간에 따른 숙련도를 모델링한, DKT(Deep Knowledge Tracing) - 논문정리 및 코드(Pytorch) (0) | 2022.12.30 |
| AIEd를 위한 학습풀이이력 공개데이터셋 (1) | 2022.12.24 |
추천시스템의 가장 기본인 협업필터링을 활용하여 교육분야에서 어떻게 활용될 수 있을 지 고민하는 시간을 가져보았습니다. 사용한 데이터는 ASSISTment 2009 데이터로, 학생별 문항 풀이이력이 존재합니다.
데이터에 대한 자세한 설명은 https://uoahvu.tistory.com/entry/AIEd를-위한-학습풀이이력-공개데이터셋 을 참고해주세요.
1. 협업필터링을 통해 특정 학습개념과 유사한 학습개념 찾기
먼저, ASSISTment 2009 데이터는 사용자별 문항 풀이이력이 존재합니다. 위 데이터 예시에서 확인할 수 있듯 해당 데이터를 통해 각 문항이 포함하는 Skill(학습 개념) 이 무엇인지, 그 문항을 맞혔는지 틀렸는 지를 확인할 수 있습니다. (맞힘 : 1 / 틀림 : 0) 보통 협업필터링은 사용자가 매긴 평점 데이터 등을 통해 사용자의 취향을 파악하기 위해 활용됩니다. 그래서 사용자들에게서 유사한 평점을 받은 컨텐츠 쌍을 유사하다고 파악하여, 특정 컨텐츠에 대해 좋은 평점을 매긴 사용자에게 그 컨텐츠와 유사도가 높은 컨텐츠들을 추천하는 방식으로 활용되고 있습니다.
그런데 문항풀이이력에서는 사용자들의 취향이라고 할만한 것들은 없습니다. 그래서 먼저, 학습 개념별 사용자들의 점수를 통해 높은 점수를 가지는 것을 강한 개념이라 하고 특정 개념에 강하다면 또 어떤 개념에 강하다고 할 수 있을 지를 파악하는 시스템을 생각해보았습니다.
적용을 위해 사용자별 개념별 점수를 계산하여 새로운 데이터프레임으로 전처리 해줍니다. 단순히 개념별 문항개수 대비 맞힌 문항 개수를 계산하여 백분율로 적용해주었습니다. 추가로, 사용자들은 모든 개념에 대한 이력이 없을 수 있기 때문에 풀이하지 않은 개념에 대한 점수는 그냥 0.0 으로 처리해주었습니다. 이는 0점인 학생과 같은 수준으로 만드는 것이기 때문에 이 둘을 구분하여 더 좋은 성능을 낼 수 있다면 고려하여 추후에 적용해보겠습니다.
skill_user_scoring = processed_df.pivot_table('score', index = 'skill_name', columns = 'user_id')
이제 그 데이터프레임에 대해 pivot_table 함수를 적용해주었습니다. 해당 함수를 통해 인덱스와 컬럼을 정해, Skill-user에 따른 점수를 표현해줍니다.
이제 이 테이블을 가지고, skill 간의 유사도를 구해보겠습니다.
from sklearn.metrics.pairwise import cosine_similarity
item_based_similarity = cosine_similarity(skill_user_scoring)
코사인 유사도를 활용했으며, sklearn에서 제공하는 cosine_similarity를 사용합니다.
item_based_similarity = pd.DataFrame(data = item_based_similarity, index = skill_user_scoring.index, columns = skill_user_scoring.index)
결과를 확인하니, 자기 자신에 대한 유사도는 1.0로 표현된 것을 확인할 수 있었습니다. 이제 이 유사도를 통해 특정 개념과 높은 유사도를 가지는 개념을 파악하기만 하면 끝입니다!
몇가지 학습개념을 직접 인퍼런스 해보았는데요. 참고로, 해당 데이터에 등장하는 개념들은 미국 수학교육과정의 단원들입니다.
<Addition and Subtraction Positive Decimals> 은 양수의 덧셈과 뺄셈입니다. 이와 유사한 개념으로 감지된 것들을 출력해보니 <Addition and Subtraction Fractions> : 분수의 덧셈과 뺄셈, <Addition and Subtraction Integers> : 정수의 덧셈과 뺄셈, <Order of Operations +,-,/,* () positive reals> : 양의 실수 연산 순서 등이 도출되었네요. 양수의 덧셈과 뺄셈을 잘하는 학생들은 해당 단원들에도 강함을 파악할 수 있었습니다. 실제로도 그럴 것 같은 개념들이 도출되어 신기하네요!
<Volume Cylinder> : 원기둥의 부피에 강한 학생들은 <Volume Sphere> : 구의 부피, <Volume Rectangular Prism> : 직각기둥의 부피, <Area trapezoid> : 사다리꼴의 면적 등, 실제로 도형과 관련한 개념들이 다수 도출됨을 확인할 수 있었습니다.
<Table> : 표 개념과 유사한 개념들은 <Mode> : 최빈값, <Median> : 중앙값, <Box and Whisker> : 박스플롯 그래프, <Range> : 범위 등 실제로 표를 통해 대표적으로 얻을 수 있는 인사이트가 포함된 개념들이 나왔습니다. 랜덤으로 몇가지를 인퍼런스 해보았는데 정말 다 직관적으로 연관성이 있는 개념들이 도출되어 신기했습니다.
반대로 특정 개념과 유사하지 않은 개념들을 뽑아보고, 그 특정 개념에 강할 때 반대로 사용자에게 약하거나 낯선 개념들을 풀어보라고 추천하는 알고리즘을 CF를 통해 구현해볼 수도 있겠다는 생각을 할 수 있었습니다!
2. 협업필터링을 통해 특정 학생와 유사한 학생 찾기
첫번째로는 학습 개념간, 즉 item-based CF 였습니다. 또 다른 CF인 user-based CF는 어떻게 활용할 수 있을지를 생각해보았고 이번에는 사용자들의 학습개념별 점수들을 통해 특정 사용자와 다른 사용자들간의 개념별 점수 유사도를 구해 유사한 수준의 사용자들을 감지해낼 수 있을 지를 확인해보겠습니다.
user_skill_scoring = processed_df.pivot_table('score', index = 'user_id', columns = 'skill_name')
이번에는 사용자를 인덱스에 두고 pivot_table을 만들어, 사용자에 대한 유사도를 구하기 위한 준비를 합니다.
from sklearn.metrics.pairwise import cosine_similarity
user_based_similarity = cosine_similarity(user_skill_scoring)user_based_similarity = pd.DataFrame(data = user_based_similarity, index = user_skill_scoring.index, columns = user_skill_scoring.index)
사용자간의 학습개념 점수를 통해 구해본 유사도 계산 결과입니다.
이처럼 사용자가 풀이한 개념별 점수에 따라 강하거나 약한 개념에 대한 수준이 유사한 사용자(코사인 유사도 기반)를 감지해보고, 이를 통해 유사한 사용자들은 어떤 문제들을 많이 틀렸는지, 어떤 개념에 강한지 등을 다양하게 파악해볼 수 있을 듯 합니다.
'AI' 카테고리의 다른 글
| Prompt Engineering 은 어떻게 하는걸까? : ChatGPT 활용 예제와 함께 완벽히 정리하기 (기본편) (1) | 2023.06.18 |
|---|---|
| Matrix Factorization : 개요와 원리부터, 최적화(SGD, ALS)까지 이해하기 (0) | 2023.06.01 |
| FM(Factorization Machines)을 활용한 학생별 문항 맞힐확률 예측하기 (0) | 2023.02.26 |
| 시간에 따른 숙련도를 모델링한, DKT(Deep Knowledge Tracing) - 논문정리 및 코드(Pytorch) (0) | 2022.12.30 |
| AIEd를 위한 학습풀이이력 공개데이터셋 (1) | 2022.12.24 |