
Factorization Machines : https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
1. Factorization Machines
오늘 다루어볼 추천모델은 Factorization Machines(이하 FM)입니다. FM은 Factorized 파라미터를 사용하여 변수간 interaction을 구한다는 것이 특징인데요, 따라서 sparse한 행렬 데이터인 경우에도 잘 적용할 수 있다는 것이 특징이자 장점입니다.

FM 논문에서는 적용예시로 영화 평점 예측 모델을 제시하고 있습니다. 위 그림처럼 각 행(row)마다 사용자별 시청 영화, 영화 평점, 시간, 지난 시청 영화를 행렬로 표현하고, 각 행에 대한 target값을 1에서 5사이의 평점으로 매기고 있습니다. 모델링을 위해 주의깊게 보아야 할 부분은 Feature vector x 입니다. 논문에서는 Feature를 원핫인코딩으로 표현하기도 하고, 정수, 혹은 합이 1인 벡터로 표현하기도 했습니다. 형태가 어찌되었든, FM은 변수간 interaction을 구해낼 것입니다.

위 수식은 2개의 특성 사이의 interaction을 모델링하기 위한 수식입니다. 해당 수식을 통해 각 쌍의 변수 조합 interaction과 단일 변수의 영향력 또한 계산하게 됩니다.
- xi는 해당 행의 i번째 x값
- w0은 global bias
- wi 는 i번째 변수의 영향력
- <vi, vj>는 i, j번재 변수간의 상호작용

여기서 놀라운 점은 FM model equation이 O(kn), 즉 선형으로 표현가능하다는 점입니다. 위 수식을 따라가면, pairwise interaction이 재구성됨을 확인할 수 있습니다. 또한 재구성된 해당 수식을 FM 모델 구현에서도 그대로 사용하게 됩니다.

따라서 FM의 그래디언트는 위와 같이 표현되며, SGD(stochastic gradient descent)를 통해 학습가능한 형태입니다.
2. FM을 통해 문항의 맞힐 확률을 구해보자!
FM 모델을 간단히 살펴보았으니, 적용해보겠습니다. 제가 사용할 데이터는 학생의 문항풀이이력입니다. ASSISTment 2009 데이터셋으로, 자세한 데이터 설명은 https://uoahvu.tistory.com/entry/AIEd를-위한-학습풀이이력-공개데이터셋을 참고해주세요.
논문의 예제에서는 영화평점 데이터를 활용했고, 해당 타겟은 1점에서 5점까지의 평점입니다. 그러나 제가 사용한 데이터는 1과 0의 정오답 타겟 데이터로, regression을 통해 맞힐 확률을 구하는 것이 가능합니다. 실제로 모델은 0혹은 1에 가깝도록 학습하는 것이니 해당 문항을 어느정도의 확률로 맞힐 것인가 정도가 되겠네요.
import pandas as pd
assist2009 = pd.read_csv('datasets/skill_builder_data.csv',encoding = 'unicode_escape')\
.dropna(subset=["skill_name"])\
.drop_duplicates(subset=["order_id", "skill_name"])\
.sort_values(by=["order_id"])\
.reset_index(drop=True).iloc[:100000]
ASSIST2009 데이터셋은 약 52만건으로, 모두 돌리기에 시간 관계상 10만건만 뽑아 진행하였습니다. order_id와 skill_name의 중복처리를 통해 학생별 문항이력이 중복된 경우를 제외했고, skill_name이 결측치인 경우를 삭제했습니다.
processed_df = assist2009[['user_id', 'skill_name', 'correct', 'hint_count']]
processed_df

모델 적용을 위해 선정한 Column은 우선 네가지 입니다. 유저아이디, 스킬이름, 정오답(타겟), 힌트사용개수입니다.
users_skill_score = processed_df.groupby(['user_id', 'skill_name'], as_index=False).mean()[['user_id', 'skill_name', 'correct']]users_skill_score = pd.pivot_table(users_skill_score,
index = 'user_id',
columns = 'skill_name',
values = 'correct')
users_skill_score
문항의 정오답에 어떤 Feature가 영향을 미칠 지 생각해보다, 학생의 개념(Skill)별 점수를 넣어주면 예측에 도움이 될 듯했습니다. 따라서 학생별 groupby 후 개념별 평균점수를 내고, pivot_table 함수를 통해 전처리했습니다.
data = pd.merge(processed_df, users_skill_score, left_on='user_id', right_on='user_id', how='left')data = pd.get_dummies(processed_df, columns = ['user_id', 'skill_name'])
data
FM 논문 속 예제와 동일하게, 유저아이디를 One-Hot 인코딩 처리하고, Skill 또한 One-Hot 인코딩했습니다. 영화평점 예제에서는 각 사용자가 어떤 영화를 보았는 지에 해당하는 것이 되겠네요. 힌트사용개수는 따로 라벨링하지 않고 그대로 사용해주었습니다.
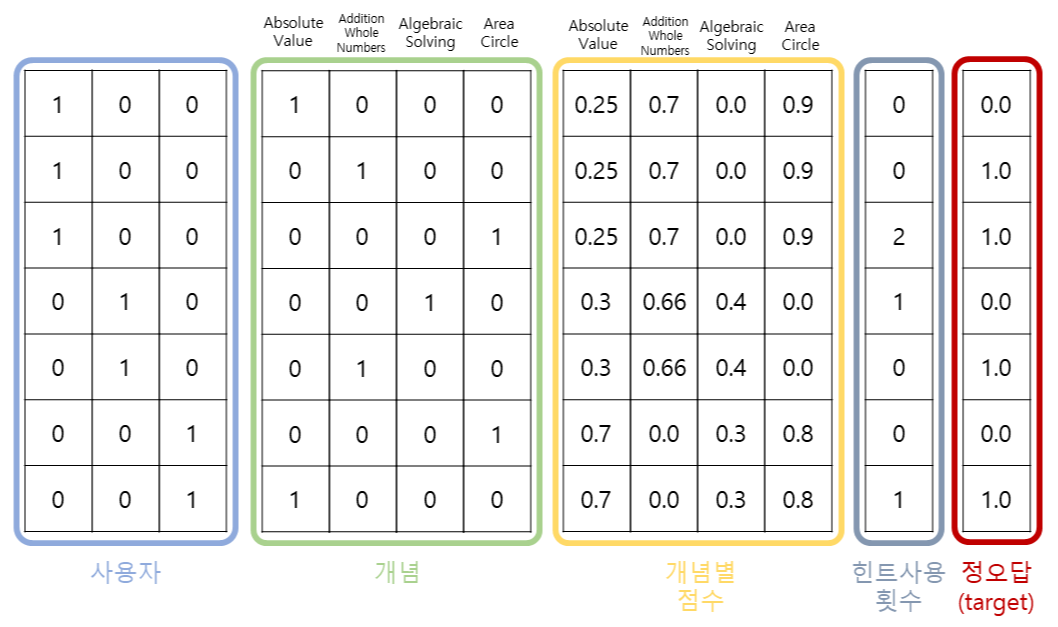
결과적으로 제가 사용한 Vector는 위 그림과 같습니다. 어떤 사용자가 어떤 개념을 풀었는 지를 원핫인코딩하고, 해당 학생의 개념(Skill)별 점수, 그리고 본 문항을 푸는데 사용한 힌트개수 입니다. 그리고 각 행을 통해 Target인 정오답을 예측해야 겠네요!
본격적으로 FM을 적용해보겠습니다.
X = data.iloc[:,1:]
Y = data['correct']
Y는 타겟값으로, 정오답입니다.
n = X.shape[0]
p = X.shape[1]
k = 10
batch_size = 128
epochs = 10class FM(tf.keras.Model):
def __init__(self):
super(FM, self).__init__()
self.w_0 = tf.Variable([0.0])
self.w = tf.Variable(tf.zeros([p]))
self.V = tf.Variable(tf.random.normal(shape=(p, k)))
def call(self, inputs):
linear_terms = tf.reduce_sum(tf.math.multiply(self.w, inputs), axis=1)
interactions = 0.5 * tf.reduce_sum(
tf.math.pow(tf.matmul(inputs, self.V), 2)
- tf.matmul(tf.math.pow(inputs, 2), tf.math.pow(self.V, 2)),
1,
keepdims=False
)
y_hat = tf.math.sigmoid(self.w_0 + linear_terms + interactions)
return y_hatdef train_on_batch(model, optimizer, accuracy, inputs, targets):
with tf.GradientTape() as tape:
y_pred = model(inputs)
loss = tf.keras.losses.binary_crossentropy(from_logits=False,
y_true=targets,
y_pred=y_pred)
grads = tape.gradient(target=loss, sources=model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
accuracy.update_state(targets, y_pred)
return loss
def train(epochs):
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, stratify=Y)
train_ds = tf.data.Dataset.from_tensor_slices(
(tf.cast(X_train, tf.float32), tf.cast(Y_train, tf.float32))).shuffle(500).batch(8)
test_ds = tf.data.Dataset.from_tensor_slices(
(tf.cast(X_test, tf.float32), tf.cast(Y_test, tf.float32))).shuffle(200).batch(8)
model = FM()
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
accuracy = BinaryAccuracy(threshold=0.5)
loss_history = []
for i in range(1, epochs+1):
for x, y in train_ds:
loss = train_on_batch(model, optimizer, accuracy, x, y)
loss_history.append(loss)
print("=========== Epoch {:03d} ===========".format(i))
print("Training Loss : {:.4f}".format(np.mean(loss_history)))
print("Training ACC : {:.4f}".format(accuracy.result().numpy()))
test_accuracy = BinaryAccuracy(threshold=0.5)
test_auc = AUC(num_thresholds=3)
for x, y in test_ds:
y_pred = model(x)
test_accuracy.update_state(y, y_pred)
test_auc.update_state(y, y_pred)
print()
print("Test ACC : {:.4f}".format(test_accuracy.result().numpy()))
print("Test AUC : {:.4f}".format(test_auc.result().numpy()))
에포크 10까지 학습해본 결과 Test 데이터셋에 대해 AUC 0.69 가량 도출되었습니다. 에포크가 진행될 때마다 Train, Test Set의 ACC가 같은 속도로 상승하는 것을 확인할 수 있었으며, 에포크를 더 늘려 학습하면 최적의 Sweet spot이 찾아질 듯 하네요.

Inference를 하면 각 row에 대한 예측값이 0에서 1사이 값으로 도출되고, 이를 해당 문항의 맞힐 확률로 간주할 수 있습니다. 저는 문항의 Skill, 힌트 사용개수 등을 사용하여 현재 풀이한 문항에 대한 예측을 진행했지만 안 푼 미래 문항에 대한 예측을 위해서라면 힌트사용개수 대신 이전에 풀이한 Skill, 지금까지의 학생의 평균 점수 등을 추가하여 목적에 따라 Feature를 선택할 수 있을 듯 합니다.
[참고]
https://greeksharifa.github.io/machine_learning/2019/12/21/FM/
Python, Machine & Deep Learning
Python, Machine Learning & Deep Learning
greeksharifa.github.io
'AI' 카테고리의 다른 글
| Prompt Engineering 은 어떻게 하는걸까? : ChatGPT 활용 예제와 함께 완벽히 정리하기 (기본편) (1) | 2023.06.18 |
|---|---|
| Matrix Factorization : 개요와 원리부터, 최적화(SGD, ALS)까지 이해하기 (0) | 2023.06.01 |
| 시간에 따른 숙련도를 모델링한, DKT(Deep Knowledge Tracing) - 논문정리 및 코드(Pytorch) (0) | 2022.12.30 |
| 협업필터링(CF)을 통해 유사한 학습개념 및 유사한 수준의 학생 찾기 (0) | 2022.12.24 |
| AIEd를 위한 학습풀이이력 공개데이터셋 (1) | 2022.12.24 |