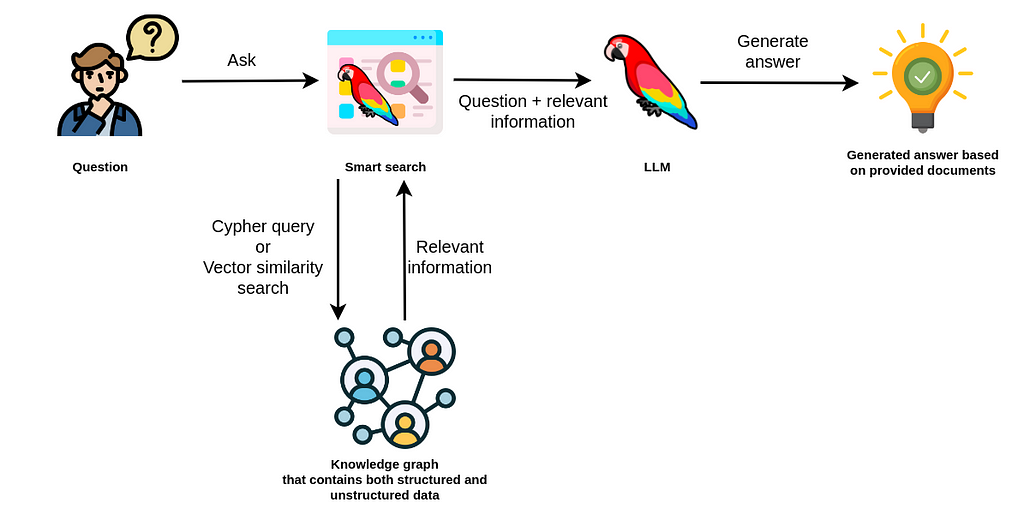
![]()
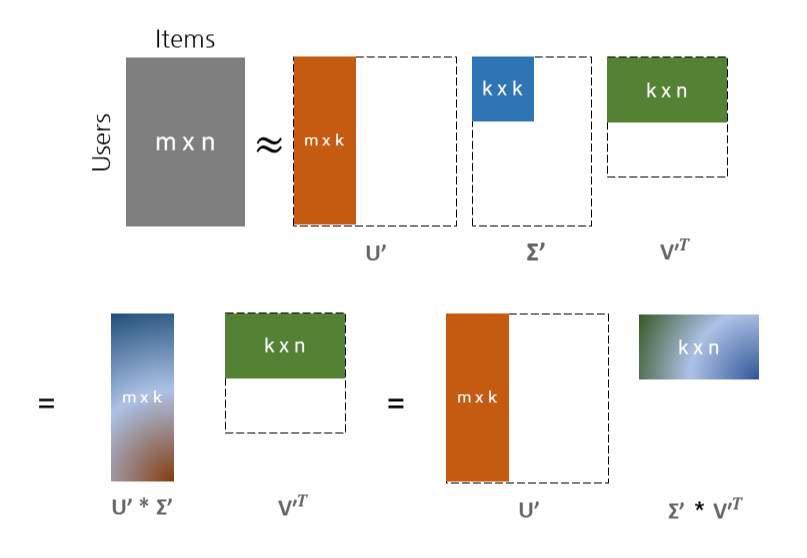
Factorization Machines : https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf 1. Factorization Machines 오늘 다루어볼 추천모델은 Factorization Machines(이하 FM)입니다. FM은 Factorized 파라미터를 사용하여 변수간 interaction을 구한다는 것이 특징인데요, 따라서 sparse한 행렬 데이터인 경우에도 잘 적용할 수 있다는 것이 특징이자 장점입니다. FM 논문에서는 적용예시로 영화 평점 예측 모델을 제시하고 있습니다. 위 그림처럼 각 행(row)마다 사용자별 시청 영화, 영화 평점, 시간, 지난 시청 영화를 행렬로 표현하고, 각 행에 대한 target값을 1에서 5사이의 평점으로..
![]()
교육분야에서의 AI는 Knowledge Tracing를 통해 적용될 수 있습니다. 그 중 Sequential Data를 사용하여 시간의 흐름에 따라 변화하는 지식 수준을 모델링한 Deep Knowledge Tracing을 살펴보겠습니다. (본 게시글은 Deep Knowledge Tracing(2015) https://papers.nips.cc/paper/2015/hash/bac9162b47c56fc8a4d2a519803d51b3-Abstract.html 을 기반으로 비전공자도 이해할 수 있도록 매우 쉽게 풀어 작성하였습니다.) 1. Knowledge Tracing Knowledge Tracing(지식 추적)이란 학생(user)의 풀이이력을 바탕으로 아직 풀이하지 않은 미래의 문제에 대해 학생의 수행결과를..
![]()
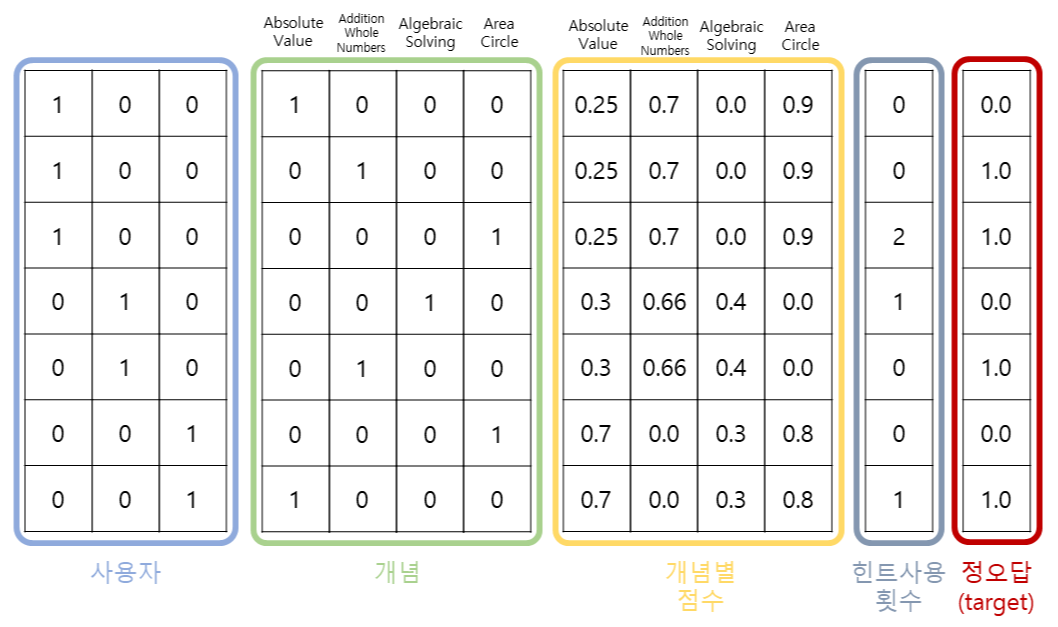
추천시스템의 가장 기본인 협업필터링을 활용하여 교육분야에서 어떻게 활용될 수 있을 지 고민하는 시간을 가져보았습니다. 사용한 데이터는 ASSISTment 2009 데이터로, 학생별 문항 풀이이력이 존재합니다. 데이터에 대한 자세한 설명은 https://uoahvu.tistory.com/entry/AIEd를-위한-학습풀이이력-공개데이터셋 을 참고해주세요. 1. 협업필터링을 통해 특정 학습개념과 유사한 학습개념 찾기 먼저, ASSISTment 2009 데이터는 사용자별 문항 풀이이력이 존재합니다. 위 데이터 예시에서 확인할 수 있듯 해당 데이터를 통해 각 문항이 포함하는 Skill(학습 개념) 이 무엇인지, 그 문항을 맞혔는지 틀렸는 지를 확인할 수 있습니다. (맞힘 : 1 / 틀림 : 0) 보통 협업필터링..
![]()
교육분야에서 인공지능을 활용하기 위해서는 가장 기본적이고 대표적으로 데이터셋이 필요합니다. 그래서 공개된 학습이력 데이터셋 5가지 정도를 공유하고자 합니다. 1. ASSISTment 2009-2010 datasets 가장 먼저, ASSISTment 2009-2010 데이터셋으로 일반적으로 Knowledge Tracing 모델 성능검증을 위해 가장 많이 사용되는 데이터 셋입니다. 해당데이터 셋은 skill_builder 와 non_skill_builder 타입 두가지로 나뉘어져 있으며, 이 중 특정 개념을 마스터 한 것으로 간주 될때는 더이상 문제를 출제하지 않았다는 skill_builder 데이터셋을 기준으로 작성하였습니다. 아래 링크에서 데이터셋을 다운로드 받을 수 있습니다. https://sites...