
GraphRAG?
최근 LLM을 잘 활용하기 위해서는 모델이 뱉어내는 텍스트를 그대로 사용하는 것이 아닌, 데이터 베이스를 직접 구축하고 그 데이터를 기반으로 LLM이 답변하도록 구현하는 RAG(Retrieval-Augmented Generation) 기법이 많이 사용되고 있습니다. 이제는 마음만 먹으면 LLM을 누구나 활용가능한 만큼, 독자적인 데이터로 사용자의 니즈에 맞춘 서비스를 준비하는 것이 더욱 관건이라는 의미인데요. 또한, 어떤 데이터 베이스를 구축하냐에 따라 그 성능이 달라지기 마련입니다.
사용자 PDF 기반 In-context Learning을 통한 ChatGPT 질의응답 챗봇 구현하기 (feat. LangChain, VectorDB)
사용자 Custom 데이터 기반 In-context Learning을 통한 질의응답 챗봇 구현하기 최근 ChatGPT의 등장으로 거대언어모델의 활용에 대해 전 세계 사람들의 이목이 쏠리고 있습니다. 특히 기업에서는 사내
uoahvu.tistory.com
기본적으로, RAG는 Vector 데이터베이스로 구축될 수 있습니다. 지난번 PDF 기반으로 질의응답을 진행하는 RAG 방식을 소개해드린 적이 있는데요. 위 방식이 Vector Store, Vector Database를 구축하여, 질의와 유사한 문서를 검색하여 해당 문서 텍스트를 기반으로 답변하는 RAG 방식으로 볼 수 있습니다.
https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
최근, Microsoft 기술 블로그에 Graph RAG 관련 글이 올라왔습니다. 단순히 벡터 데이터베이스 기반의 Retrieval 방식의 유사도 검색이 아닌, Knowledge Graph를 구축해 더 세분화된 지식 검색을 하는 것이 중요해졌는데요. 본 블로그에서는 베이스 RAG에 비해 GraphRAG를 사용하면 각기 분리된 정보의 조각들을 연결하고, 대규모 문서에 대한 전체적인 이해가 필요한 문제상황에서 상당한 개선을 보여준다고 언급하고 있습니다.
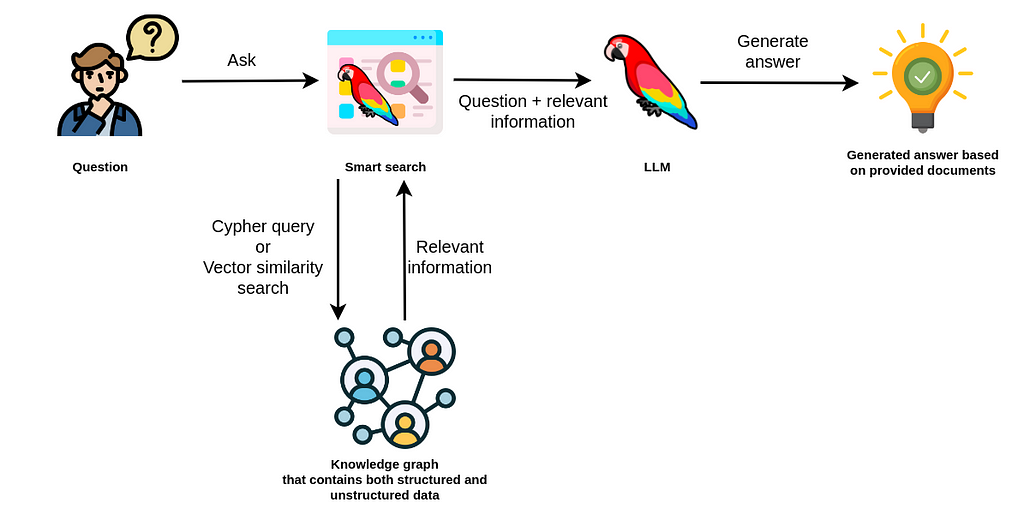
위 그림은 GraphRAG가 진행되는 과정을 표현한 것입니다. 사용자가 질의를 하면, Cypher query*, 혹은 Vector 유사도 검색을 통해 구축되어 있는 Knowledge Graph에 접근해 관련된 정보를 찾아옵니다. 해당 정보를 기반으로 질문에 대한 답을 LLM이 해주게 됩니다. Base RAG와 다른 점은 Knowledge Graph에 접근한다는 점이며, Graph에는 텍스트뿐 아니라 다양한 메타데이터들과 관계(Relationship) 들이 저장되어 있다는 점입니다.
* Cypher : Cypher란, Graph 데이터베이스에 접근하기 위해 사용되는 그래프 쿼리 언어
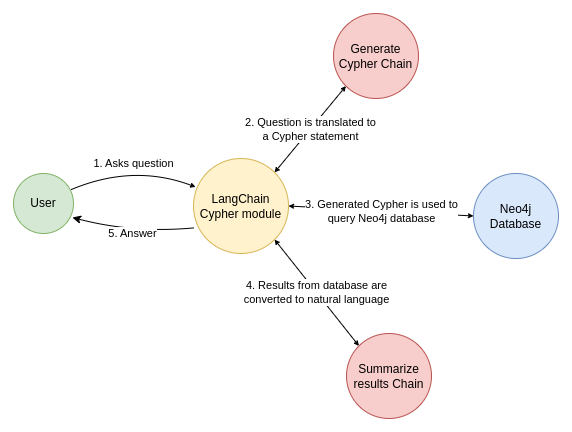
Neo4j(Graph Database Management System)에서도 GraphRAG를 직접 데모를 통해 보여주고 있습니다. ( https://neo4j.com/labs/genai-ecosystem/rag-demo/ ) 위 그림은 데모 사이트에서 가져온 그림인데요. Neo4j 를 활용한 GraphRAG를 어떻게 구현할 수 있을지를 좀 더 상세히 확인할 수 있습니다.
Neo4j는 Graph를 구축하는데 활용, 이 외 LLM과 데이터베이스를 연결하기 위해서는 LangChain을 사용하게 됩니다. 먼저, Knowledge Graph에 접근하기 위해서는 Cypher 쿼리를 날려야 한다고 했습니다. 그 Cypher 쿼리문을 작성하는 것 자체를 LLM에 맡겨 진행합니다. 이게 그림상에서 2번에 해당합니다.
그리고 그 Cypher 쿼리문을 Neo4j DB에 접근해 결과를 얻어오고, 얻어온 결과를 기반으로 LLM이 질문에 대한 답변을 하면 끝입니다.
이 과정을 잘 기억하면서, 좀 더 상세히 LangChain에서 GraphRAG를 위해 제공하는 모듈과, 그 내부 동작 원리를 하나씩 살펴보도록 하겠습니다. 🛫
GraphRAG 구현하기
앞에서 언급한 대로, Langchain에서는 거대언어모델(LLM)을 사용하여, 그래프 쿼리 언어인 Cypher로 Graph DB에 접근해 QA를 진행하는 모듈을 제공하고 있으며, 공식 파이썬 Docs에서 상세한 내용을 확인할 수 있습니다. 해당 내용을 기반으로 GraphRAG를 순서대로 구현해 보겠습니다.
https://python.langchain.com/docs/use_cases/graph/graph_cypher_qa
Neo4j DB QA chain | 🦜️🔗 Langchain
This notebook shows how to use LLMs to provide a natural language
python.langchain.com
📌 Neo4j GraphDB 구축
Graph DB 구축은 Neo4j로 진행하며, 저는 Neo4j Sandbox를 활용했습니다.
Neo4j Sandbox란 온라인 그래프 데이터베이스로, 무료 클라우드 기반 Neo4j 인스턴스를 구축할 수 있기 때문에 간편하게 리소스를 빌려 그래프 DB를 실험할 수 있습니다.
Home - Neo4j Sandbox
sandbox.neo4j.com
Sandbox에 접속하여, + New Project 버튼을 클릭해 원하는 데이터셋을 골라 DB를 생성할 수 있습니다.
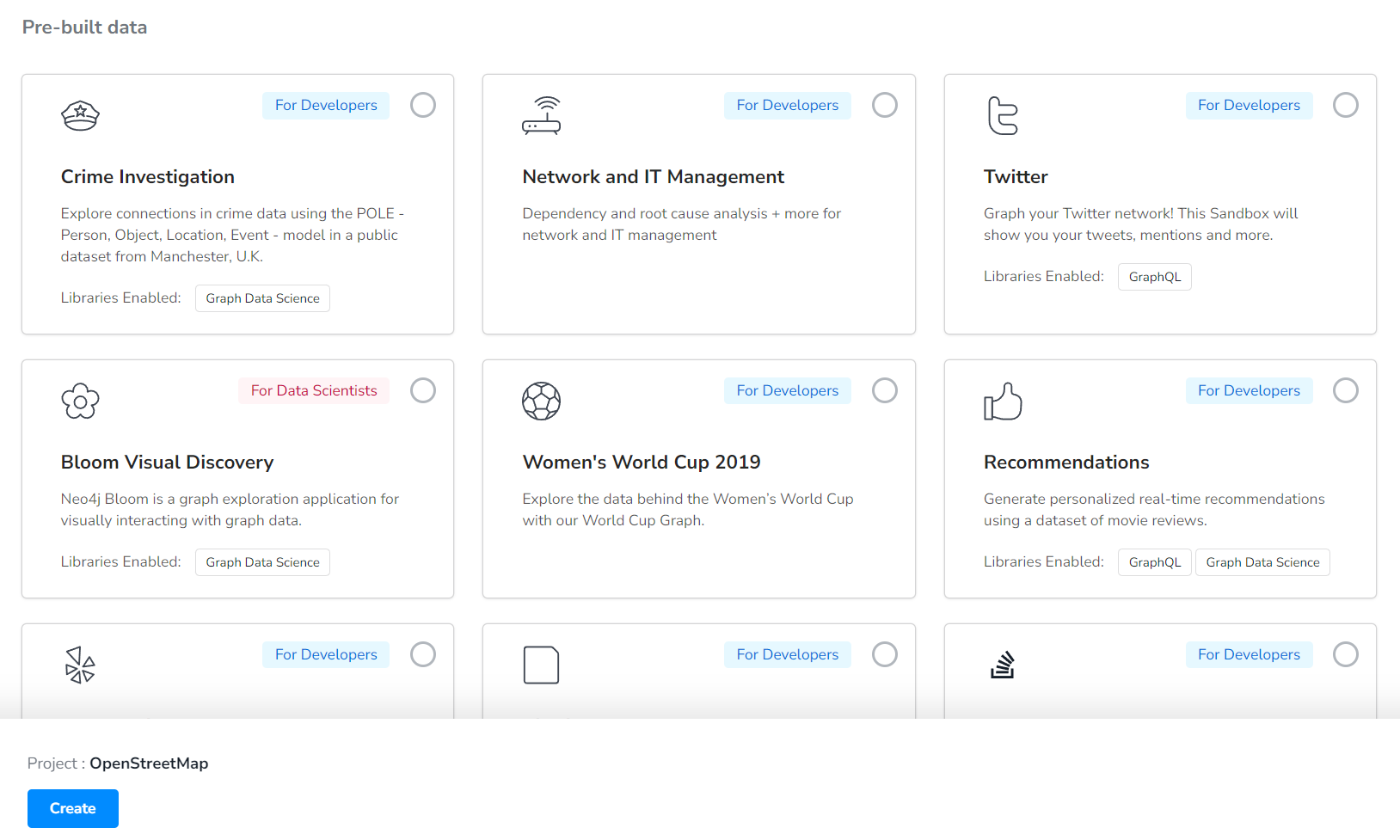
각종 다양한 데이터셋들을 확인할 수 있고, Blank Sandbox 선택 시 사용자 데이터셋 (csv 등)을 업로드하여 GraphDB를 직접 온라인으로 구축하실 수도 있습니다.
우선은, 가장 기본적으로 제공하는 Movie Dataset을 사용하겠습니다.

생성 후 토글을 눌러보면 Neo4j 연결을 위한 예제 코드들을 언어별로 제공해 줍니다. neo4j-driver 라이브러리를 설치해 쉽게 연결이 가능하며, 코드를 복사+붙여넣기 하여 바로 사용할 수 있습니다. 아래 코드 참조 [1]
[1] neo4j-driver를 통한 Sandbox GraphDB 연동 확인
from neo4j import GraphDatabase, basic_auth
graph = GraphDatabase.driver(
"bolt://44.204.92.102:7687",
auth=basic_auth("neo4j", "example-web-coin"))
cypher_query = '''
MATCH (movie:Movie {title:$favorite})<-[:ACTED_IN]-(actor)-[:ACTED_IN]->(rec:Movie)
RETURN distinct rec.title as title LIMIT 10
'''
with graph.session(database="neo4j") as session:
results = session.read_transaction(
lambda tx: tx.run(cypher_query,
favorite="The Matrix").data())
for record in results:
print(record['title'])
graph.close()

Langchain에서 GraphDB를 불러오기 위해서는, Connection details 부분만 확인하면 됩니다. 연결을 위한 Username, Password, Bolt URL 정보를 복사해 사용해 줄 겁니다.
📌 Langchain을 활용한 GraphRAG 구현
GraphCypherQAChain
Langchain에서는 여러 가지 Chains을 제공합니다. 이름에서도 느껴지듯 LLM, DB 등을 연결해 주는 것을 의미하는 데요. GraphRAG 구현을 위해서는 GraphCypherQAChain을 사용할 수 있습니다. 아래부터는 실행 코드와 함께 설명을 이어가려 하며, 모든 코드는 아래 colab 링크에서 확인하실 수 있습니다.
https://colab.research.google.com/drive/1vVcdcn3MeZCkFoeLLWy4kBCZ4SXaxlHz?usp=sharing
Langchain - GraphCypherQAChain.ipynb
Colaboratory notebook
colab.research.google.com
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
GraphDB와 LLM연결을 위한 Chain, Neo4j Graph 모듈, ChatGPT API 연결을 위한 ChatOpenAI를 임포트 해주었습니다.
GraphRAG를 구현하기 위해서는 먼저 cypher 쿼리문으로 관련 그래프 정보를 가져와야 했습니다. 이를 위해 GraphCypherQAChain에서는 LLM을 통해 먼저 Cypher 쿼리문을 생성하고, 생성된 쿼리문으로 GraphDB에 접근해 데이터를 뽑아오는데요. 그렇다면 이때 LLM에 어떤 프롬프트가 입력되는지 살펴보겠습니다.
1) Prompt (프롬프트)
Langchain github[2] 를 통해 Cypher 쿼리문을 통한 QA가 어떻게 지시되고 있는지 프롬프트를 통해 확인할 수 있었습니다.
💡 step1. Cypher 쿼리문 생성
CYPHER_GENERATION_TEMPLATE = """Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
The question is:
{question}"""
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"], template=CYPHER_GENERATION_TEMPLATE
)Task: 그래프 데이터베이스를 쿼리하기 위한 Cypher 문을 생성합니다.
Instructions:
스키마에는 제공된 관계 유형 및 속성만 사용하세요.
제공되지 않은 다른 관계 유형이나 속성을 사용하지 마십시오.
Schema:
{schema}
Note: 답변에 설명이나 사과를 포함하지 마세요.
Cypher 문을 구성하는 것 외에 다른 질문을 할 수 있는 질문에는 응답하지 마세요.
생성된 Cypher 문을 제외한 어떤 텍스트도 포함하지 마세요.
The question is:
{question}
먼저, Cypher 쿼리문을 생성하는 프롬프트 템플릿입니다. Input으로 GraphDB의 Schema와 Question(질문 텍스트)가 들어가야 합니다. 이때, Schema는 내부의 construct_schema 함수[3]를 통해 Node properites 와 Relationship properties, Relationships 들을 String 형태로 프롬프트에 예쁘게 들어갈 수 있도록 가공됩니다. 아래 처럼요!
Node properties are the following: Person {name: STRING, born: INTEGER},Movie {tagline: STRING, title: STRING, released: INTEGER}
Relationship properties are the following: ACTED_IN {roles: LIST},REVIEWED {summary: STRING, rating: INTEGER}
The relationships are the following: (:Person)-[:ACTED_IN]->(:Movie),(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:PRODUCED]->(:Movie),(:Person)-[:WROTE]->(:Movie),(:Person)-[:FOLLOWS]->(:Person),(:Person)-[:REVIEWED]->(:Movie)
답변에 참조할 GraphDB의 Node의 이름과 프로퍼티의 데이터타입, Relationship 의 이름과 프로퍼티 데이터 타입을 확인할 수 있으며, Node들이 어떤 식으로 관계(Relationship)를 맺고 있는 지 확인할 수 있습니다.
💡 step2. 생성한 Cypher 쿼리문을 통한 Question & Answering
CYPHER_QA_TEMPLATE = """You are an assistant that helps to form nice and human understandable answers.
The information part contains the provided information that you must use to construct an answer.
The provided information is authoritative, you must never doubt it or try to use your internal knowledge to correct it.
Make the answer sound as a response to the question. Do not mention that you based the result on the given information.
Here is an example:
Question: Which managers own Neo4j stocks?
Context:[manager:CTL LLC, manager:JANE STREET GROUP LLC]
Helpful Answer: CTL LLC, JANE STREET GROUP LLC owns Neo4j stocks.
Follow this example when generating answers.
If the provided information is empty, say that you don't know the answer.
Information:
{context}
Question: {question}
Helpful Answer:"""
CYPHER_QA_PROMPT = PromptTemplate(
input_variables=["context", "question"], template=CYPHER_QA_TEMPLATE
)당신은 훌륭하고 인간이 이해할 수 있는 답변을 만드는 데 도움을 주는 조수입니다.
정보 부분에는 답변을 구성하는 데 사용해야 하는 제공된 정보가 포함되어 있습니다.
제공된 정보는 권위가 있으므로 이를 의심하거나 내부 지식을 사용하여 수정하려고 해서는 안 됩니다.
대답을 질문에 대한 응답으로 들리게 만드십시오. 주어진 정보를 바탕으로 결과를 도출했다고 언급하지 마십시오.
예는 다음과 같습니다.
Question: Neo4j 주식을 소유한 관리자는 누구입니까?
Context:[manager:CTL LLC, manager:JANE STREET GROUP LLC]
Helpful Answer: CTL LLC, JANE STREET GROUP LLC는 Neo4j 주식을 소유하고 있습니다.
답변을 생성할 때 이 예를 따르십시오.
제공된 정보가 비어 있으면 답을 모른다고 말하세요.
Information:
{context}
Question: {question}
Helpful Answer:
이번에는, 생성된 Cypher 쿼리문과 Question을 참고하여 질문에 답을 할 차례입니다. Input으로 context 와 question이 들어가는 것을 확인할 수 있는데요. context는 위에서 생성한 cypher 쿼리문을 graph에 쿼리한 결과를 넣어줍니다.[4] 만약 쿼리 결과가 없다면, context는 빈 리스트를 갖게 되는데요. 그럼 프롬프트에 따라 LLM은 "답을 모른다" 라는 답을 내뱉을 겁니다.
최종적으로 LLM은 question 내용으로 생성된 cypher 쿼리문으로부터 받은 graph 쿼리 결과를 기반으로, 사용자의 질문(question)에 대한 답을 내놓게 됩니다.
[2] GraphQA prompts.py
[3] construct_schema
: https://github.com/langchain-ai/langchain/blob/ced5e7bae790cd9ec4e5374f5d070d9f23d6457b/libs/langchain/langchain/chains/graph_qa/cypher.py#L39C6-L39C21
[4] context (generated_cypher)
2) Graph 연결
graph = Neo4jGraph(url="bolt://44.204.92.102:7687", username="neo4j", password="example-web-coin")
다시 코드로 돌아왔습니다. 위에서 확인한 Langchain 내부 코드가 동작되기 위해서는 우리가 구축한 GraphDB를 연결해주어야겠죠. 처음에 Neo4j Sandbox 로 만들었던 GraphDB의 url 주소와 Usernaem, Password 까지 복사해왔다면, 위 코드에 붙여넣어 주기만 하면 됩니다.
느낌이 오겠지만, Neo4jGraph 클래스[5]를 통해 Neo4j Graph 인스턴스를 생성할 수 있습니다. 그래프 DB 정보를 파라미터로 입력해주었고, 해당 정보를 받아 graph 변수로 사용할 수 있게 되었습니다.
이렇게 생성된 GraphDB 인스턴스는 query 메소드를 통해 쿼리할 수 있습니다.

Cypher 문을 통해 쿼리를 날리고, 쿼리 결과가 리스트 속 딕셔너리 형태로 반환되는 것을 확인할 수 있습니다.
[5] langchain_community.graphs.neo4j_graph.Neo4jGraph
3) LLM QA
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
이제, GraphCypherQAChain 에서 제공하는 메소드를 통해 QA를 진행하기만 하면 됩니다. 바로 from_llm 인데요. 기본적으로 사용할 LLM 모델과, Graph 인스턴스가 파라미터로 들어가게 됩니다.
LLM 파라미터로 들어간 ChatOpenAI 는 OpenAI에서 제공하는 model 을 불러오기 위한 API[6]입니다. gpt-3.5-turbo 모델이 default 이며, OpenAI API Key가 필요합니다. (코랩 코드 참조)
(참조) ChatOpenAI 사용법
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0,
max_tokens=2048,
model_name='gpt-3.5-turbo',
)
question = 'ChatGPT가 뭐야?'
print(llm.predict(question))ChatGPT는 OpenAI가 개발한 자연어 처리 기술을 기반으로 한 대화형 인공지능 챗봇입니다. ChatGPT는 사용자와 자연스럽게 대화하며 질문에 답변하고 다양한 주제에 대해 이야기할 수 있습니다. 이러한 챗봇은 온라인 상에서 고객 서비스, 정보 제공, 엔터테인먼트 등 다양한 용도로 활용될 수 있습니다.
다시 돌아와서, GraphCypherQAChain 객체를 만들어줬었습니다. run 메소드를 통해 사용자 question 과 함께 바로 GraphRAG를 실현할 수 있습니다.
chain.run("Who played in Top Gun?")[output] Val Kilmer, Meg Ryan, Tom Skerritt, Kelly McGillis, Tom Cruise, Anthony Edwards played in Top Gun.
먼저, Top Gun 영화에 누가 등장하는 지를 물어보았는데요. 영화의 제목(title)을 'Top Gun'으로 제한해주고, 이 때 이 영화에 등장한 (ACTED_IN relationship) 사람을 p 로 받아와 Name을 출력하도록하는 Cypher문이 생성되었습니다. 실행결과 총 6명의 사람 이름이 도출되었고, 이 배우들의 이름을 답변해주고 있습니다.
chain.run("How many people played in Top Gun?")[output] 6 people played in Top Gun.
이번에는 Top Gun 영화에 몇명이 등장하는 지를 물어보았는데요. 명수를 물어보았기 때문에 COUNT 함수를 사용해주고 있습니다.
이렇게, 기대했던 대로 사용자의 질문을 이해한 Cypher 문을 생성해주고, 생성한 Cypher 쿼리의 결과 (Full context)를 토대로 답변을 내어주는 모습입니다.
[6] LangChain ChatOpenAI
: https://python.langchain.com/docs/integrations/chat/openai
Kaggle Amazon Fine Food Reviews 데이터셋으로 GraphRAG 구현하기
이제 그럼, Neo4j에서 제공하는 데이터셋이 아닌 외부 데이터셋으로 GraphRAG를 구현하며 마무리해보겠습니다.
https://www.kaggle.com/datasets/snap/amazon-fine-food-reviews/data
Amazon Fine Food Reviews
Analyze ~500,000 food reviews from Amazon
www.kaggle.com
위 데이터셋은 Amazon 의 Fine Food들에 대한 리뷰 데이터셋입니다. 2012년 10월까지의 약 50만개 리뷰를 포함하고 있으며, 10년 이상의 기간에 걸쳐 수집되었다고 합니다.

제공되는 Reviews.csv 데이터셋에는 각 row를 구분하는 Id 부터 시작해, 아래의 컬럼들을 가지고 있습니다.
- 상품의 Id (ProductId)
- 사용자 Id (UserId)
- 사용자 프로필이름 (ProfileName)
- 리뷰가 도움이 된 사람들의 수 (HelpfulnessNumerator)
- 리뷰가 도움이 되었는지에 대한 답변을 한 사람들의 수 (HelpfulnessDenominator)
- 상품에 대한 1점~5점 사이의 점수 (Score)
- 리뷰를 등록한 시점 (Time)
- 리뷰 요약 (Summary)
- 리뷰 텍스트 (Text)
사용자들이 매긴 리뷰 각각을 식별하는 ID와 함께 데이터를 확인할 수 있습니다.
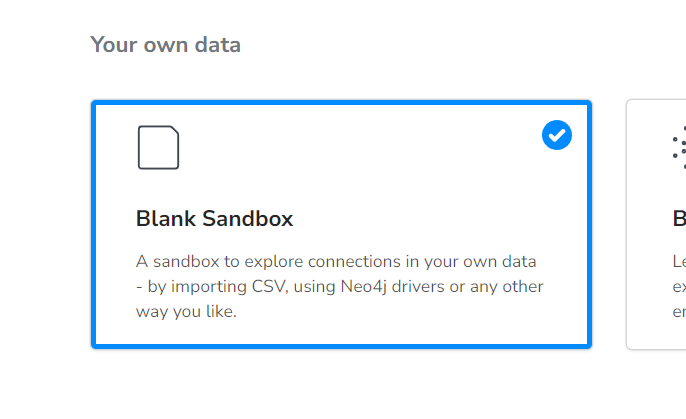
이 데이터셋을 Knowledge Graph로 구축해보려 하는데요. 앞에서 사용했던 Neo4j Sandbox에서 이번에는 <Blank Sandbox>를 선택해주면 됩니다. 아래 설명 처럼, 본인의 CSV 데이터셋 임포팅을 통해 Graph DB 적재가 가능하다고 되어있네요.
📌 CSV Dataset Importing 하기
데이터 임포팅은 neo4j의 data-importer 를 활용했습니다. 아래 링크를 통해 접속이 가능합니다.
https://data-importer.neo4j.io/versions/0.7.0/
Neo4j Workspace
data-importer.neo4j.io
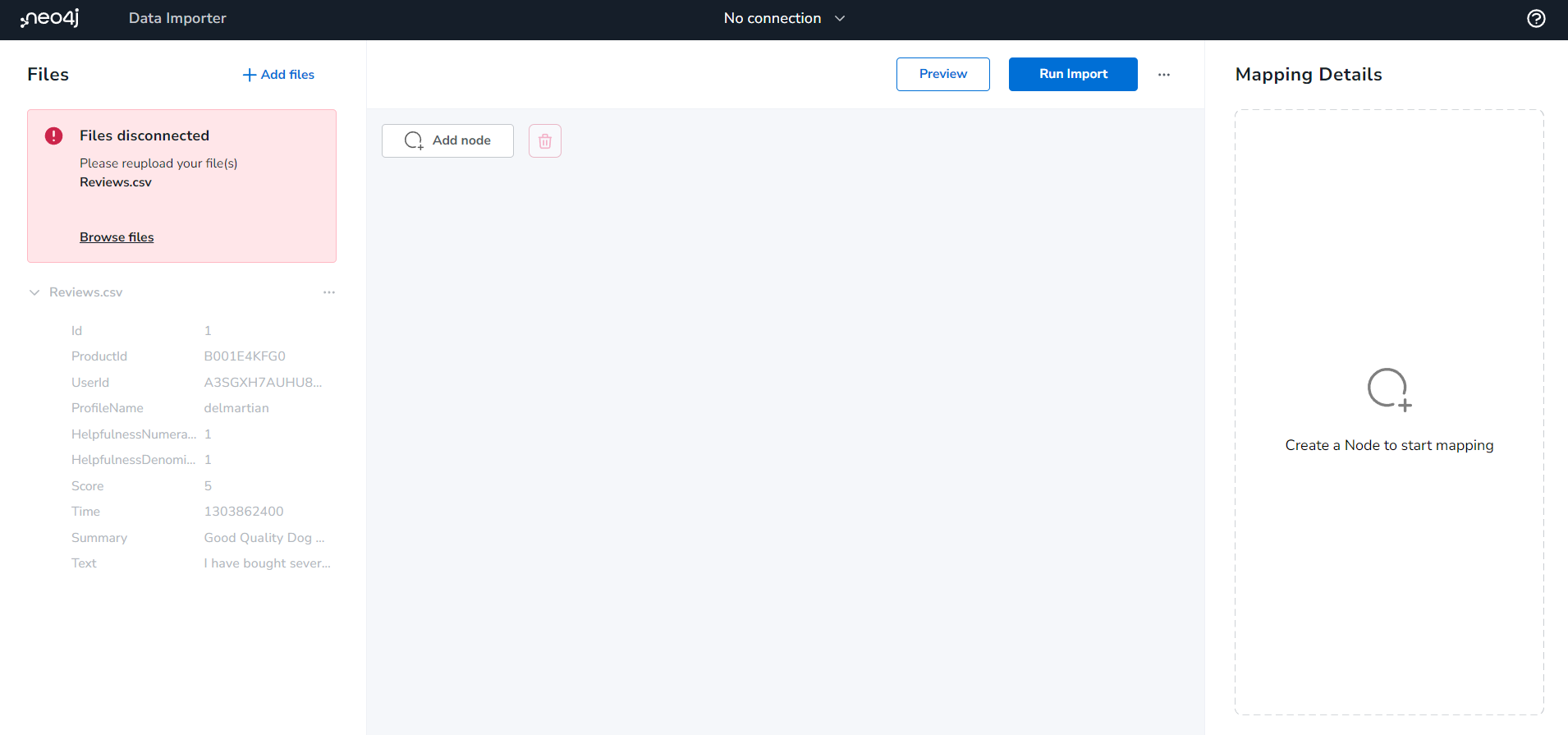
사이트에 들어가면 이런 화면을 확인할 수 있는데요. 중앙 상단에 <No connection>은 현재 Graph DB와 연결되어 있지 않다는 뜻입니다. 따라서 클릭하여 DB 정보를 입력해주셔야 합니다.
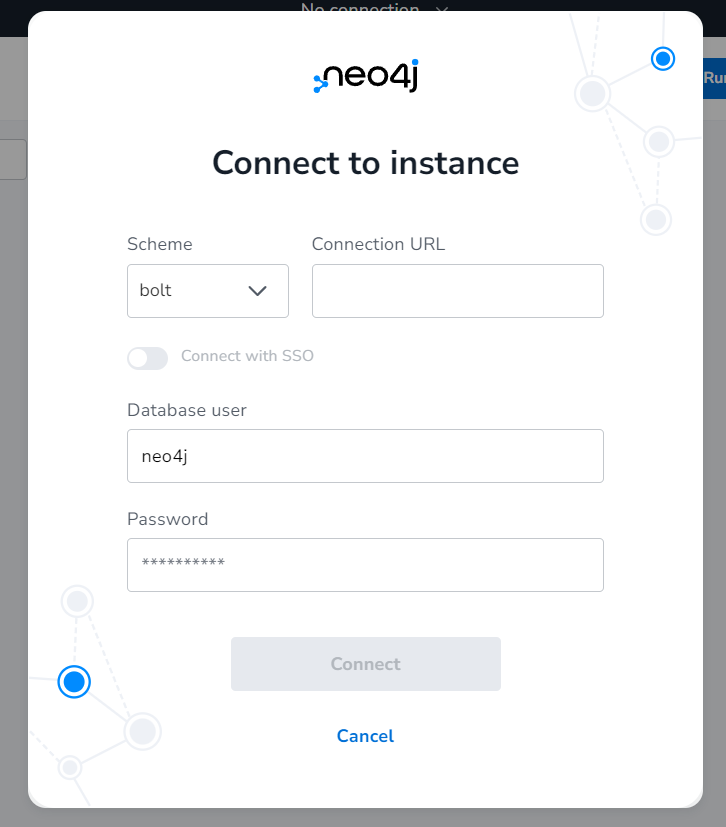
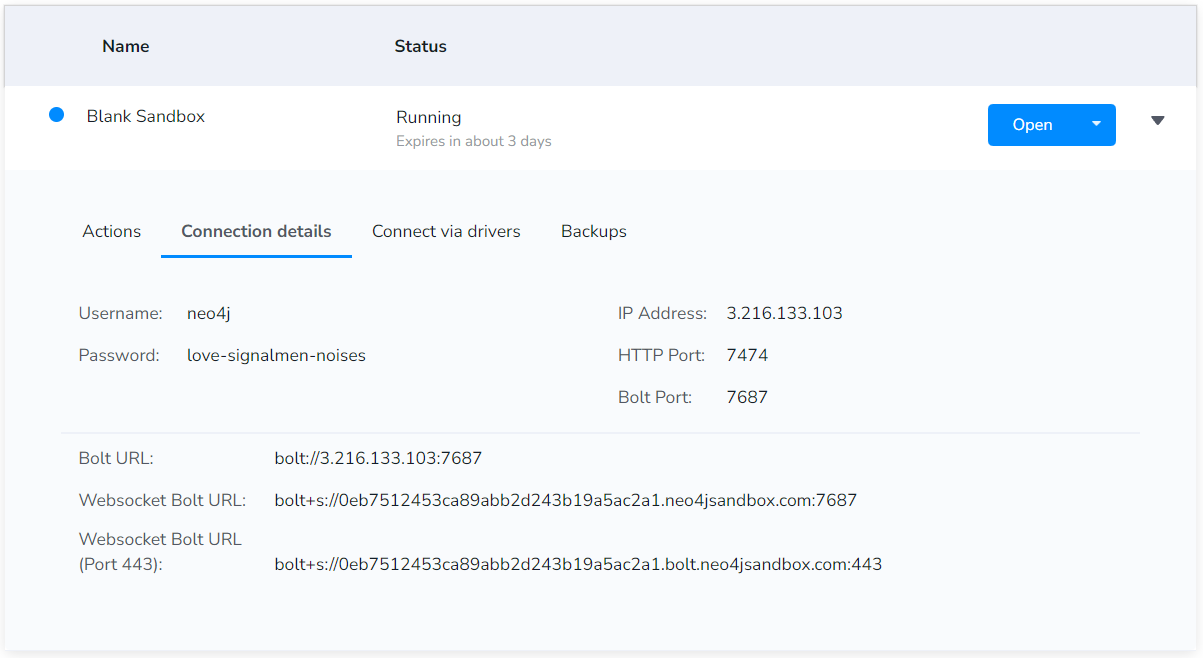
DB 정보는 Sandbox 상에서 확인할 수 있었습니다. 우리가 필요한 것은 하단에 Websocket Bolt URL 입니다. 해당 URL을 그대로 복사하여 붙여넣어주시면 됩니다. Username과 Password도 당연히 필요하겠죠!
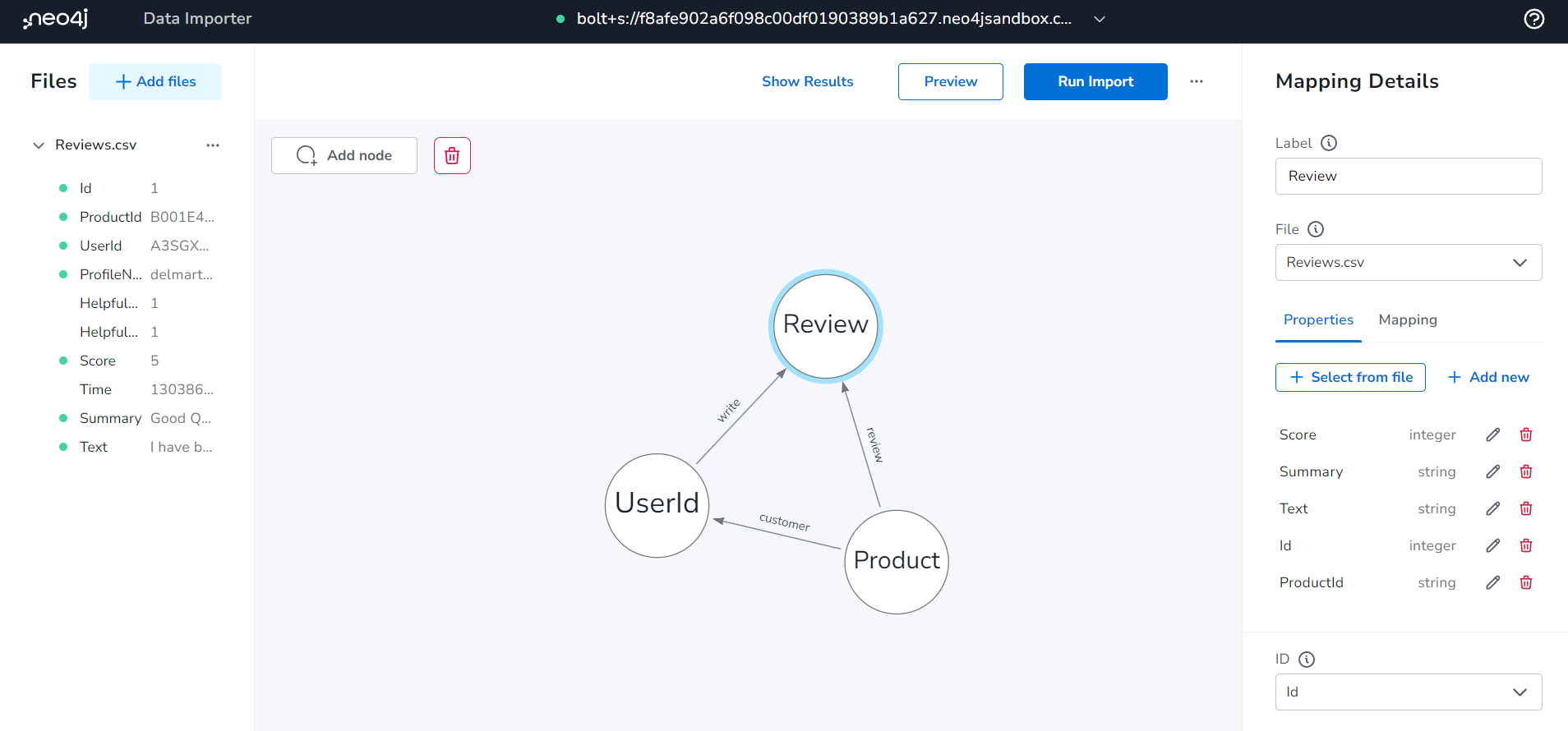
연결을 해주었다면 왼쪽 상단에 보이는 +Add files 버튼을 눌러 사용하고자 하는 CSV 파일을 업로드 해주시면 됩니다. 저는 Reviews.csv 를 업로드 했고, 업로드 하면 간단히 어떤 컬럼을 가지고 있는 데이터인지, 샘플데이터와 함께 좌측에서 확인할 수 있습니다.
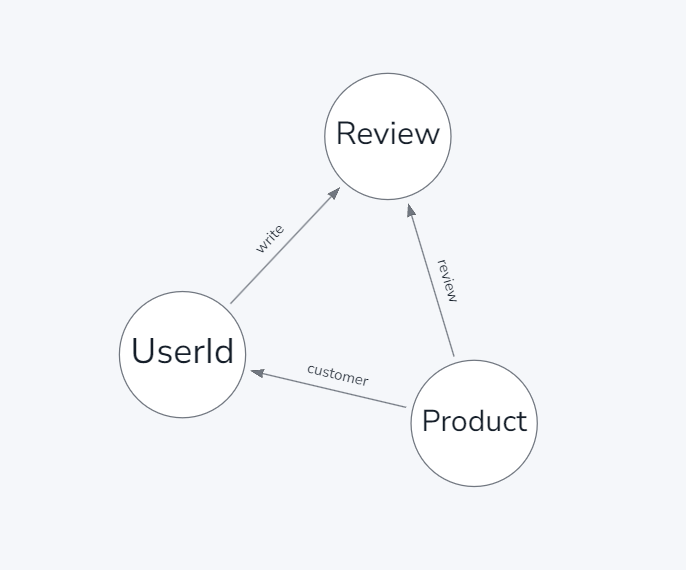
Amazon Fine Food Reviews 데이터 같은 경우, 크게 세가지의 노드로 만들 수 있었습니다. 사용자 정보를 담는 User, 상품의 정보를 담는 Product, 리뷰 정보를 담는 Review입니다.
그리고 Product는 해당상품을 구매한 사용자 정보와 연결되는 customer라는 관계를, User는 어떤 리뷰를 작성했는 지를 연결하는 write 관계를 생성하였으며, 상품은 어떤 리뷰들을 가지고 있는 지를 확인할 수 있도록 Review와 연결되는 review 관계를 연결해주었습니다.
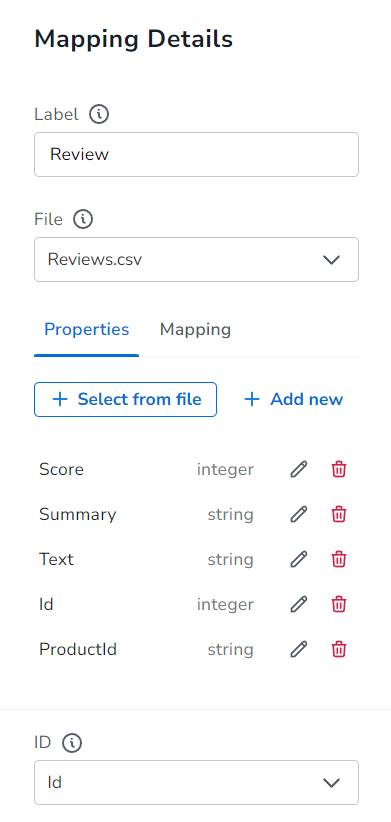
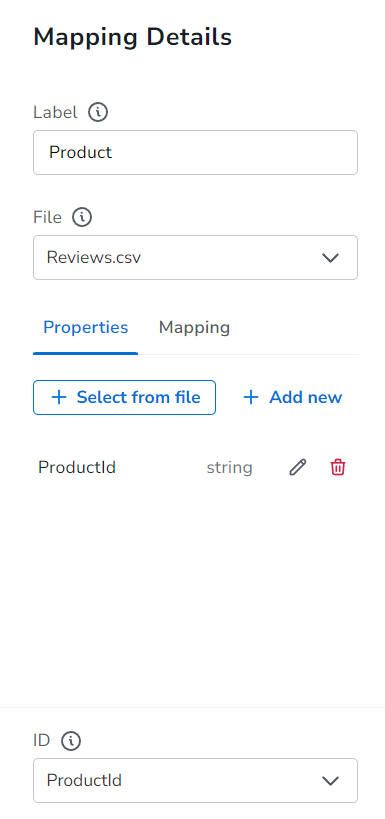
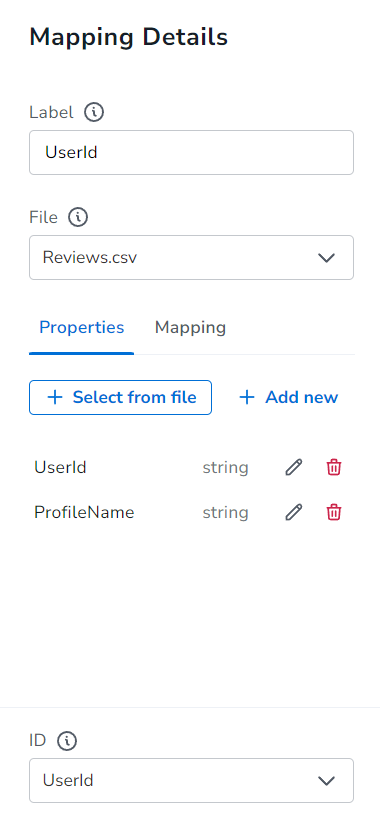
노드들의 Property 까지 설정해주었다면, 화면 상단의 Run Import 버튼을 눌러 데이터 임포팅을 시작합니다!
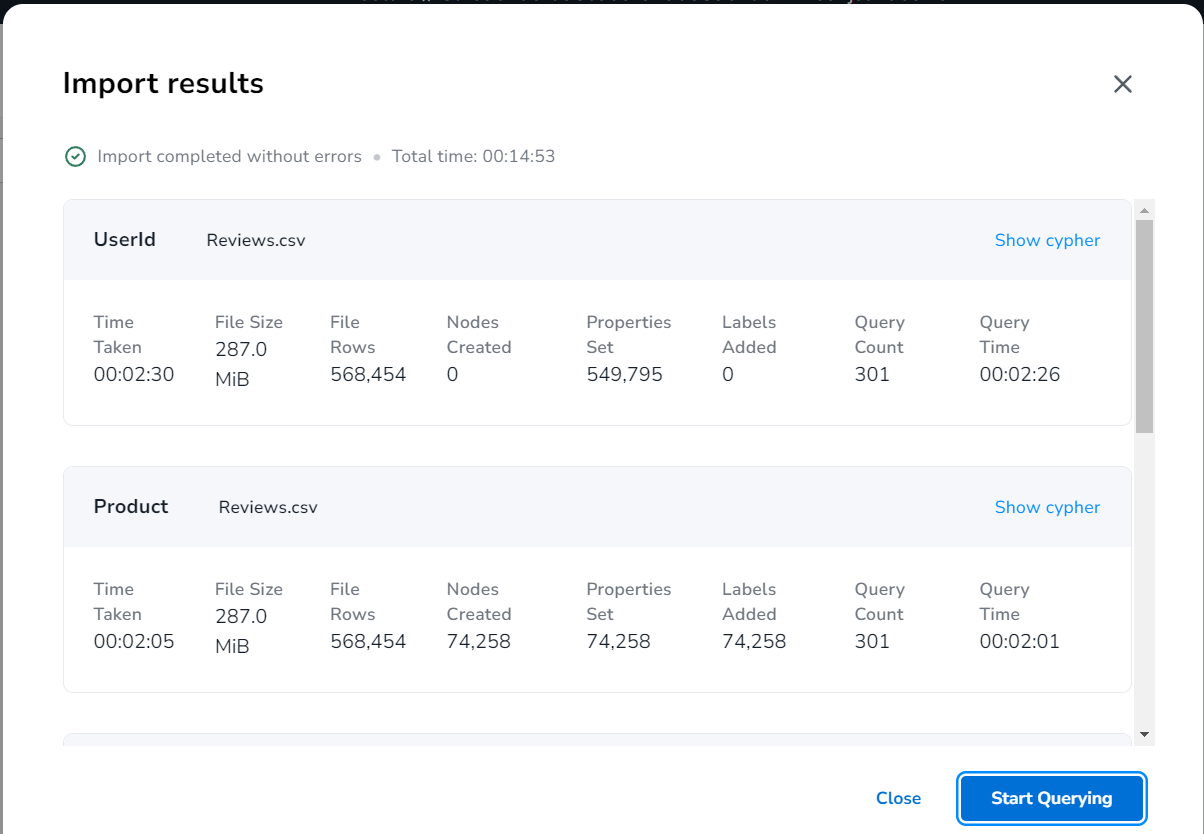
임포팅이 완료되었네요. Graph DB에 데이터가 성공적으로 적재되었습니다.
📌 GraphRAG 질의응답 테스트
구축한 GraphDB를 통해 몇가지 질문을 던져, 제대로 검색하여 답변을 잘 생성해내는 지 확인해 보았습니다.
MATCH (p:Product)-->(u:UserId)-->(r:Review)
WHERE p.ProductId = 'B000EPP56U'
RETURN p,u,r LIMIT 100

먼저, 구축한 Graph DB를 통해 검색하면 이런 느낌인데요. 저는 B000EPP56U 라는 ID를 가진 상품에 대해 어떤 사용자들이 리뷰를 남겼고, 또 그 사용자가 어떤 리뷰들을 남겼는 지를 확인하는 쿼리문으로 시각화를 먼저 진행해보았습니다. 사용자와 상품, 리뷰들이 얽혀 시각화 된 것을 확인할 수 있습니다. 그럼 이 복잡한 관계를 지닌 데이터셋에서 원하는 정보만 빼서 질의해보아야겠죠.
1. 데이터 집계에 대한 질의

기본적으로, 구축한 Graph DB에 데이터들이 어떻게 저장되어있는 지 집계와 관련한 질의들을 몇가지 해보았습니다. 먼저, B000EPP56U 상품은 몇개의 리뷰를 가지고 있는 지 질문해보았는데요. 아래와 같은 cypher 쿼리문을 생성해냈습니다.
MATCH (:Product {ProductId: 'B000EPP56U'})-[:review]->(r:Review)
RETURN COUNT(r) as NumberOfReviews;
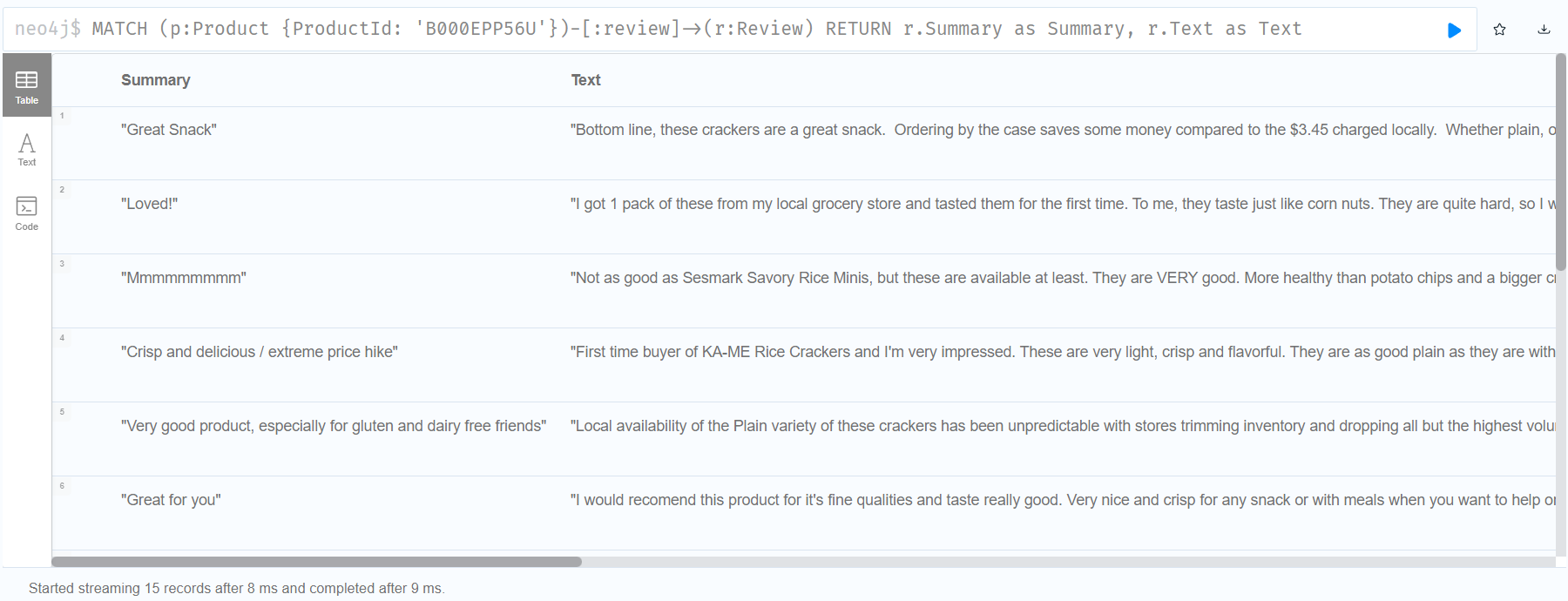
ProductId가 B000EPP56U 인 Product가 review라는 관계를 가지는 Review 노드를 몇개 가지고 있는지, 그 Review 노드를 r 이라고 했을 때 COUNT(r)을 하여 노드의 개수를 세는 쿼리문을 완벽히 작성해냈습니다.
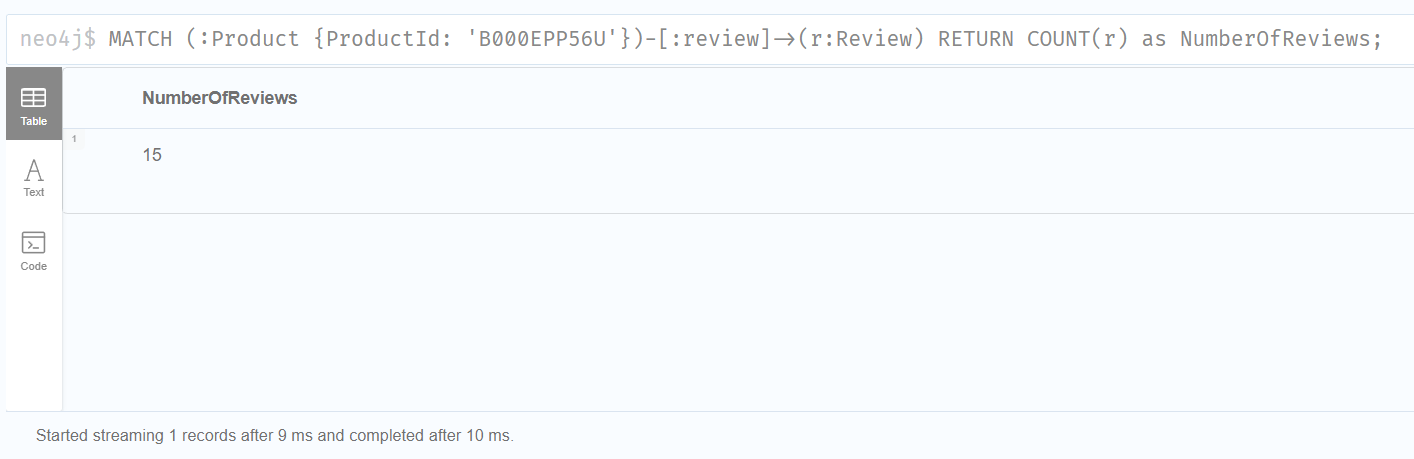
실제로 neo4j desktop을 통해 결과를 확인한 결과, 15개라는 결과를 얻을 수 있었고, 해당 결과를 통해 LLM에게 'The B000EPP56U product has 15 reviews.' 라는 답변을 얻을 수 있었습니다.
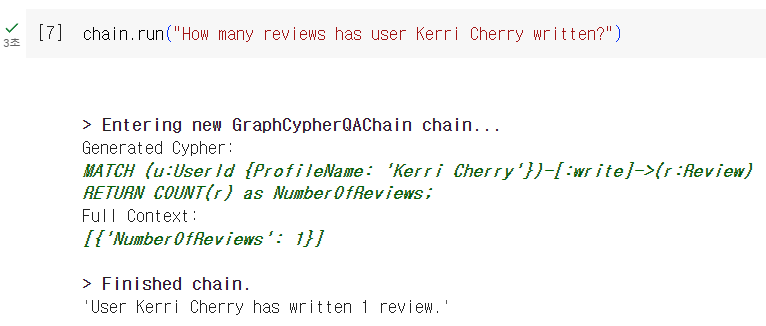
비슷하게, Kerri Cherry 라는 사용자가 몇개의 리뷰를 썼는 지를 물어보았습니다. 마찬가지로 ProfileName이 Kerri Cherry 인 사용자가 Review 노드를 몇개 가지고 있는 지를 검색하는 Cypher 쿼리문을 잘 생성하였습니다.
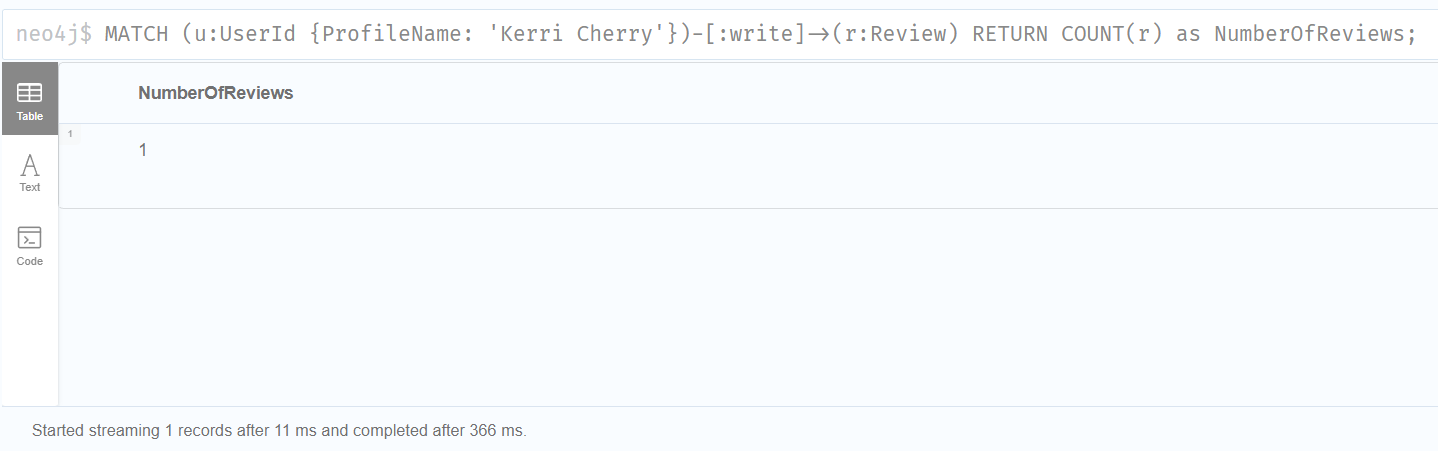
결과가 1이기 때문에 'User Kerri Cherry has written 1 review.' 라는 답변을 얻었습니다.
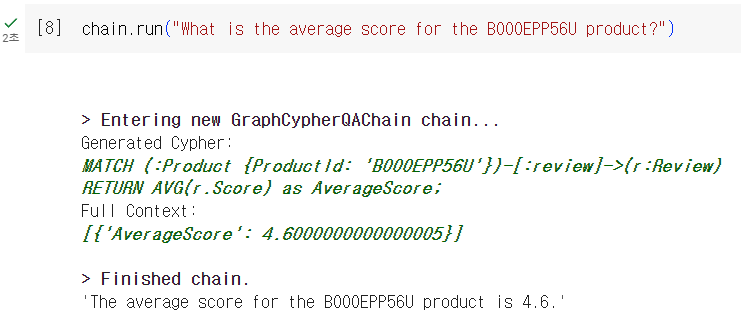
이번에는 B000EPP56U 상품이 평균 몇점을 가지고 있는 지를 물어보았는데요. 각 리뷰는 텍스트 뿐 아니라 Score라고 하는 1점부터 5점까지의 평점 정보가 있었습니다. 생성된 Cypher 문을 보니 우선 B000EPP56U 상품이 가지고 있는 리뷰를 모두 찾아, 해당 리뷰의 Score property의 평균을 구하기 위해 AVG 함수를 사용해주었습니다.

실제로 쿼리문을 날려본 결과 4.6 점이라는 평균 평점을 확인할 수 있었고 이 결과를 토대로 LLM은 'The average score for the B000EPP56U product is 4.6.' 이라는 답변을 도출했습니다.

실제로 시각화도 해보았는데요, 검색된 노드들의 평점 평균들을 직접 계산기를 통해 확인해보았는데.. 4.6점이 맞았습니다. ㅎㅎ
2. 데이터 활용에 대한 질의
이번에는 단순히 검색을 통해 알 수 있는 집계에 대한 질의가 아닌, 검색된 데이터로 LLM에 좀 더 책임이 있는 질문들을 해보려 합니다.
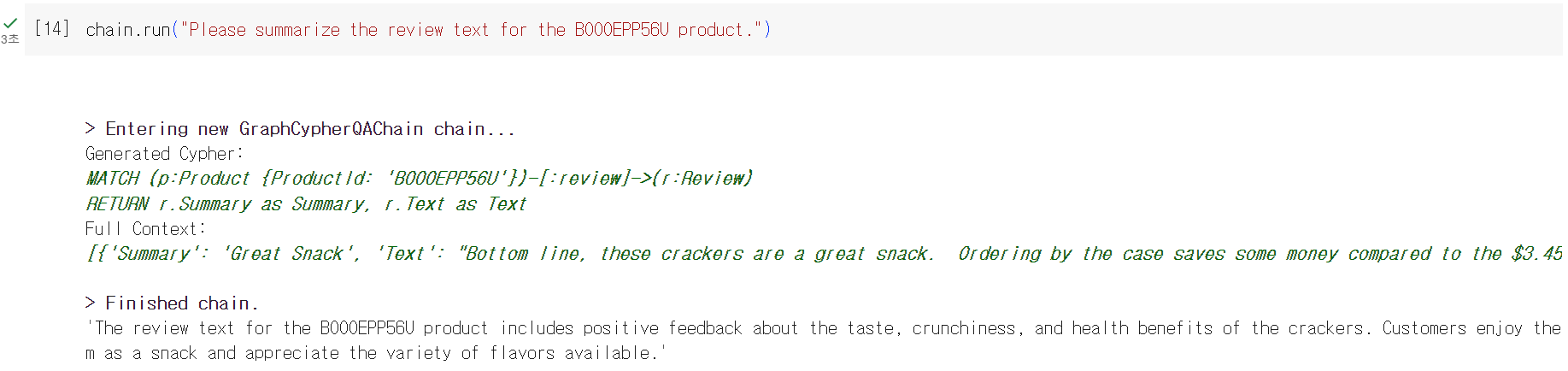
먼저, B000EPP56U 상품의 리뷰들을 요약하게 했습니다. 생성된 Cypher 문을 보니 리뷰 노드의 Summary와 Text Property를 불러왔고, 두 Property는 리뷰의 요약 텍스트와, 전체 텍스트 입니다. 이제 이 결과를 기반으로 이후에는 LLM이 리뷰의 요약을 하여 적절한 답변을 내어주었습니다.
'The review text for the B000EPP56U product includes positive feedback about the taste, crunchiness, and health benefits of the crackers. Customers enjoy them as a snack and appreciate the variety of flavors available.'
실제로 리뷰 텍스트에 있던 내용들을 기반으로 요약을 해주는 것을 확인할 수 있었습니다.
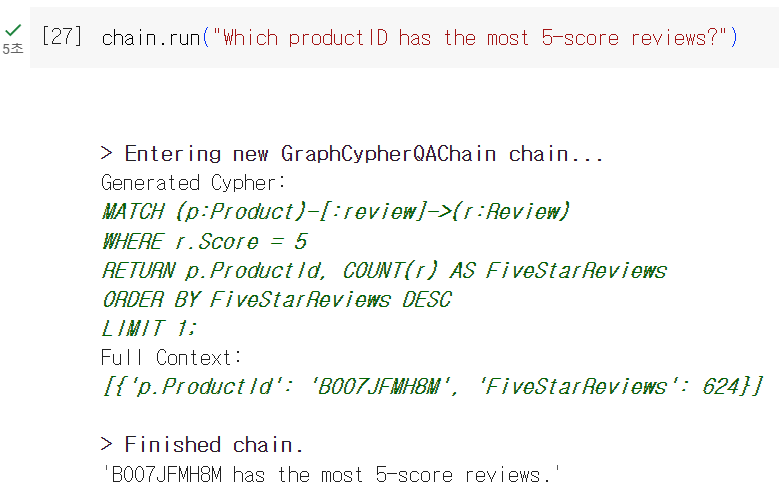
다음은 5점인 리뷰가 가장 많은 상품은 어떤 것인지, 즉 가장 만족도가 높은 상품은 무엇인지에 대해 질문해보았습니다. 생성된 cypher문을 확인하면, WHERE절을 통해 Score 를 5로 제한하고, Review 노드의 카운팅을 통해 개수가 많은 순대로 정렬하여, 가장 상단의 상품 정보를 얻어왔습니다.

쿼리 실행 결과 B007JFMH8M 이라는 상품이 가장 5점 리뷰를 많이 받았고, 최종적으로 ' B007JFMH8M has the most 5-score reviews.' 라는 답변을 얻을 수 있었습니다.
이번 포스팅에서는 LangChain과 Neo4j를 활용한 기본적인 GraphQA 구현부터, 캐글 데이터셋을 직접 임포팅해 나만의 GraphRAG를 구현해보았습니다. LangChain과 함께라면 뭐든 할 수 있겠다는 걸 또 느낀 경험이었습니다. 앞으로는 얼마나 더 섬세한 데이터 저장과 검색이 가능해질 지 그 발전이 기대됩니다.
제가 실험한 코드는 아래 코랩을 통해 모두 확인 가능합니다. 감사합니다 😊
https://colab.research.google.com/drive/1kd0aNCEawk6PpQDpBRhf7rEPbGpROPXy?usp=sharing
GraphRAG - Own Dataset.ipynb
Colaboratory notebook
colab.research.google.com
'AI' 카테고리의 다른 글
GraphRAG?
최근 LLM을 잘 활용하기 위해서는 모델이 뱉어내는 텍스트를 그대로 사용하는 것이 아닌, 데이터 베이스를 직접 구축하고 그 데이터를 기반으로 LLM이 답변하도록 구현하는 RAG(Retrieval-Augmented Generation) 기법이 많이 사용되고 있습니다. 이제는 마음만 먹으면 LLM을 누구나 활용가능한 만큼, 독자적인 데이터로 사용자의 니즈에 맞춘 서비스를 준비하는 것이 더욱 관건이라는 의미인데요. 또한, 어떤 데이터 베이스를 구축하냐에 따라 그 성능이 달라지기 마련입니다.
사용자 PDF 기반 In-context Learning을 통한 ChatGPT 질의응답 챗봇 구현하기 (feat. LangChain, VectorDB)
사용자 Custom 데이터 기반 In-context Learning을 통한 질의응답 챗봇 구현하기 최근 ChatGPT의 등장으로 거대언어모델의 활용에 대해 전 세계 사람들의 이목이 쏠리고 있습니다. 특히 기업에서는 사내
uoahvu.tistory.com
기본적으로, RAG는 Vector 데이터베이스로 구축될 수 있습니다. 지난번 PDF 기반으로 질의응답을 진행하는 RAG 방식을 소개해드린 적이 있는데요. 위 방식이 Vector Store, Vector Database를 구축하여, 질의와 유사한 문서를 검색하여 해당 문서 텍스트를 기반으로 답변하는 RAG 방식으로 볼 수 있습니다.
https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
최근, Microsoft 기술 블로그에 Graph RAG 관련 글이 올라왔습니다. 단순히 벡터 데이터베이스 기반의 Retrieval 방식의 유사도 검색이 아닌, Knowledge Graph를 구축해 더 세분화된 지식 검색을 하는 것이 중요해졌는데요. 본 블로그에서는 베이스 RAG에 비해 GraphRAG를 사용하면 각기 분리된 정보의 조각들을 연결하고, 대규모 문서에 대한 전체적인 이해가 필요한 문제상황에서 상당한 개선을 보여준다고 언급하고 있습니다.
위 그림은 GraphRAG가 진행되는 과정을 표현한 것입니다. 사용자가 질의를 하면, Cypher query*, 혹은 Vector 유사도 검색을 통해 구축되어 있는 Knowledge Graph에 접근해 관련된 정보를 찾아옵니다. 해당 정보를 기반으로 질문에 대한 답을 LLM이 해주게 됩니다. Base RAG와 다른 점은 Knowledge Graph에 접근한다는 점이며, Graph에는 텍스트뿐 아니라 다양한 메타데이터들과 관계(Relationship) 들이 저장되어 있다는 점입니다.
* Cypher : Cypher란, Graph 데이터베이스에 접근하기 위해 사용되는 그래프 쿼리 언어
Neo4j(Graph Database Management System)에서도 GraphRAG를 직접 데모를 통해 보여주고 있습니다. ( https://neo4j.com/labs/genai-ecosystem/rag-demo/ ) 위 그림은 데모 사이트에서 가져온 그림인데요. Neo4j 를 활용한 GraphRAG를 어떻게 구현할 수 있을지를 좀 더 상세히 확인할 수 있습니다.
Neo4j는 Graph를 구축하는데 활용, 이 외 LLM과 데이터베이스를 연결하기 위해서는 LangChain을 사용하게 됩니다. 먼저, Knowledge Graph에 접근하기 위해서는 Cypher 쿼리를 날려야 한다고 했습니다. 그 Cypher 쿼리문을 작성하는 것 자체를 LLM에 맡겨 진행합니다. 이게 그림상에서 2번에 해당합니다.
그리고 그 Cypher 쿼리문을 Neo4j DB에 접근해 결과를 얻어오고, 얻어온 결과를 기반으로 LLM이 질문에 대한 답변을 하면 끝입니다.
이 과정을 잘 기억하면서, 좀 더 상세히 LangChain에서 GraphRAG를 위해 제공하는 모듈과, 그 내부 동작 원리를 하나씩 살펴보도록 하겠습니다. 🛫
GraphRAG 구현하기
앞에서 언급한 대로, Langchain에서는 거대언어모델(LLM)을 사용하여, 그래프 쿼리 언어인 Cypher로 Graph DB에 접근해 QA를 진행하는 모듈을 제공하고 있으며, 공식 파이썬 Docs에서 상세한 내용을 확인할 수 있습니다. 해당 내용을 기반으로 GraphRAG를 순서대로 구현해 보겠습니다.
https://python.langchain.com/docs/use_cases/graph/graph_cypher_qa
Neo4j DB QA chain | 🦜️🔗 Langchain
This notebook shows how to use LLMs to provide a natural language
python.langchain.com
📌 Neo4j GraphDB 구축
Graph DB 구축은 Neo4j로 진행하며, 저는 Neo4j Sandbox를 활용했습니다.
Neo4j Sandbox란 온라인 그래프 데이터베이스로, 무료 클라우드 기반 Neo4j 인스턴스를 구축할 수 있기 때문에 간편하게 리소스를 빌려 그래프 DB를 실험할 수 있습니다.
Home - Neo4j Sandbox
sandbox.neo4j.com
Sandbox에 접속하여, + New Project 버튼을 클릭해 원하는 데이터셋을 골라 DB를 생성할 수 있습니다.
각종 다양한 데이터셋들을 확인할 수 있고, Blank Sandbox 선택 시 사용자 데이터셋 (csv 등)을 업로드하여 GraphDB를 직접 온라인으로 구축하실 수도 있습니다.
우선은, 가장 기본적으로 제공하는 Movie Dataset을 사용하겠습니다.
생성 후 토글을 눌러보면 Neo4j 연결을 위한 예제 코드들을 언어별로 제공해 줍니다. neo4j-driver 라이브러리를 설치해 쉽게 연결이 가능하며, 코드를 복사+붙여넣기 하여 바로 사용할 수 있습니다. 아래 코드 참조 [1]
[1] neo4j-driver를 통한 Sandbox GraphDB 연동 확인
from neo4j import GraphDatabase, basic_auth
graph = GraphDatabase.driver(
"bolt://44.204.92.102:7687",
auth=basic_auth("neo4j", "example-web-coin"))
cypher_query = '''
MATCH (movie:Movie {title:$favorite})<-[:ACTED_IN]-(actor)-[:ACTED_IN]->(rec:Movie)
RETURN distinct rec.title as title LIMIT 10
'''
with graph.session(database="neo4j") as session:
results = session.read_transaction(
lambda tx: tx.run(cypher_query,
favorite="The Matrix").data())
for record in results:
print(record['title'])
graph.close()
Langchain에서 GraphDB를 불러오기 위해서는, Connection details 부분만 확인하면 됩니다. 연결을 위한 Username, Password, Bolt URL 정보를 복사해 사용해 줄 겁니다.
📌 Langchain을 활용한 GraphRAG 구현
GraphCypherQAChain
Langchain에서는 여러 가지 Chains을 제공합니다. 이름에서도 느껴지듯 LLM, DB 등을 연결해 주는 것을 의미하는 데요. GraphRAG 구현을 위해서는 GraphCypherQAChain을 사용할 수 있습니다. 아래부터는 실행 코드와 함께 설명을 이어가려 하며, 모든 코드는 아래 colab 링크에서 확인하실 수 있습니다.
https://colab.research.google.com/drive/1vVcdcn3MeZCkFoeLLWy4kBCZ4SXaxlHz?usp=sharing
Langchain - GraphCypherQAChain.ipynb
Colaboratory notebook
colab.research.google.com
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
GraphDB와 LLM연결을 위한 Chain, Neo4j Graph 모듈, ChatGPT API 연결을 위한 ChatOpenAI를 임포트 해주었습니다.
GraphRAG를 구현하기 위해서는 먼저 cypher 쿼리문으로 관련 그래프 정보를 가져와야 했습니다. 이를 위해 GraphCypherQAChain에서는 LLM을 통해 먼저 Cypher 쿼리문을 생성하고, 생성된 쿼리문으로 GraphDB에 접근해 데이터를 뽑아오는데요. 그렇다면 이때 LLM에 어떤 프롬프트가 입력되는지 살펴보겠습니다.
1) Prompt (프롬프트)
Langchain github[2] 를 통해 Cypher 쿼리문을 통한 QA가 어떻게 지시되고 있는지 프롬프트를 통해 확인할 수 있었습니다.
💡 step1. Cypher 쿼리문 생성
CYPHER_GENERATION_TEMPLATE = """Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
The question is:
{question}"""
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"], template=CYPHER_GENERATION_TEMPLATE
)Task: 그래프 데이터베이스를 쿼리하기 위한 Cypher 문을 생성합니다.
Instructions:
스키마에는 제공된 관계 유형 및 속성만 사용하세요.
제공되지 않은 다른 관계 유형이나 속성을 사용하지 마십시오.
Schema:
{schema}
Note: 답변에 설명이나 사과를 포함하지 마세요.
Cypher 문을 구성하는 것 외에 다른 질문을 할 수 있는 질문에는 응답하지 마세요.
생성된 Cypher 문을 제외한 어떤 텍스트도 포함하지 마세요.
The question is:
{question}
먼저, Cypher 쿼리문을 생성하는 프롬프트 템플릿입니다. Input으로 GraphDB의 Schema와 Question(질문 텍스트)가 들어가야 합니다. 이때, Schema는 내부의 construct_schema 함수[3]를 통해 Node properites 와 Relationship properties, Relationships 들을 String 형태로 프롬프트에 예쁘게 들어갈 수 있도록 가공됩니다. 아래 처럼요!
Node properties are the following: Person {name: STRING, born: INTEGER},Movie {tagline: STRING, title: STRING, released: INTEGER}
Relationship properties are the following: ACTED_IN {roles: LIST},REVIEWED {summary: STRING, rating: INTEGER}
The relationships are the following: (:Person)-[:ACTED_IN]->(:Movie),(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:PRODUCED]->(:Movie),(:Person)-[:WROTE]->(:Movie),(:Person)-[:FOLLOWS]->(:Person),(:Person)-[:REVIEWED]->(:Movie)
답변에 참조할 GraphDB의 Node의 이름과 프로퍼티의 데이터타입, Relationship 의 이름과 프로퍼티 데이터 타입을 확인할 수 있으며, Node들이 어떤 식으로 관계(Relationship)를 맺고 있는 지 확인할 수 있습니다.
💡 step2. 생성한 Cypher 쿼리문을 통한 Question & Answering
CYPHER_QA_TEMPLATE = """You are an assistant that helps to form nice and human understandable answers.
The information part contains the provided information that you must use to construct an answer.
The provided information is authoritative, you must never doubt it or try to use your internal knowledge to correct it.
Make the answer sound as a response to the question. Do not mention that you based the result on the given information.
Here is an example:
Question: Which managers own Neo4j stocks?
Context:[manager:CTL LLC, manager:JANE STREET GROUP LLC]
Helpful Answer: CTL LLC, JANE STREET GROUP LLC owns Neo4j stocks.
Follow this example when generating answers.
If the provided information is empty, say that you don't know the answer.
Information:
{context}
Question: {question}
Helpful Answer:"""
CYPHER_QA_PROMPT = PromptTemplate(
input_variables=["context", "question"], template=CYPHER_QA_TEMPLATE
)당신은 훌륭하고 인간이 이해할 수 있는 답변을 만드는 데 도움을 주는 조수입니다.
정보 부분에는 답변을 구성하는 데 사용해야 하는 제공된 정보가 포함되어 있습니다.
제공된 정보는 권위가 있으므로 이를 의심하거나 내부 지식을 사용하여 수정하려고 해서는 안 됩니다.
대답을 질문에 대한 응답으로 들리게 만드십시오. 주어진 정보를 바탕으로 결과를 도출했다고 언급하지 마십시오.
예는 다음과 같습니다.
Question: Neo4j 주식을 소유한 관리자는 누구입니까?
Context:[manager:CTL LLC, manager:JANE STREET GROUP LLC]
Helpful Answer: CTL LLC, JANE STREET GROUP LLC는 Neo4j 주식을 소유하고 있습니다.
답변을 생성할 때 이 예를 따르십시오.
제공된 정보가 비어 있으면 답을 모른다고 말하세요.
Information:
{context}
Question: {question}
Helpful Answer:
이번에는, 생성된 Cypher 쿼리문과 Question을 참고하여 질문에 답을 할 차례입니다. Input으로 context 와 question이 들어가는 것을 확인할 수 있는데요. context는 위에서 생성한 cypher 쿼리문을 graph에 쿼리한 결과를 넣어줍니다.[4] 만약 쿼리 결과가 없다면, context는 빈 리스트를 갖게 되는데요. 그럼 프롬프트에 따라 LLM은 "답을 모른다" 라는 답을 내뱉을 겁니다.
최종적으로 LLM은 question 내용으로 생성된 cypher 쿼리문으로부터 받은 graph 쿼리 결과를 기반으로, 사용자의 질문(question)에 대한 답을 내놓게 됩니다.
[2] GraphQA prompts.py
[3] construct_schema
: https://github.com/langchain-ai/langchain/blob/ced5e7bae790cd9ec4e5374f5d070d9f23d6457b/libs/langchain/langchain/chains/graph_qa/cypher.py#L39C6-L39C21
[4] context (generated_cypher)
2) Graph 연결
graph = Neo4jGraph(url="bolt://44.204.92.102:7687", username="neo4j", password="example-web-coin")
다시 코드로 돌아왔습니다. 위에서 확인한 Langchain 내부 코드가 동작되기 위해서는 우리가 구축한 GraphDB를 연결해주어야겠죠. 처음에 Neo4j Sandbox 로 만들었던 GraphDB의 url 주소와 Usernaem, Password 까지 복사해왔다면, 위 코드에 붙여넣어 주기만 하면 됩니다.
느낌이 오겠지만, Neo4jGraph 클래스[5]를 통해 Neo4j Graph 인스턴스를 생성할 수 있습니다. 그래프 DB 정보를 파라미터로 입력해주었고, 해당 정보를 받아 graph 변수로 사용할 수 있게 되었습니다.
이렇게 생성된 GraphDB 인스턴스는 query 메소드를 통해 쿼리할 수 있습니다.
Cypher 문을 통해 쿼리를 날리고, 쿼리 결과가 리스트 속 딕셔너리 형태로 반환되는 것을 확인할 수 있습니다.
[5] langchain_community.graphs.neo4j_graph.Neo4jGraph
3) LLM QA
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
이제, GraphCypherQAChain 에서 제공하는 메소드를 통해 QA를 진행하기만 하면 됩니다. 바로 from_llm 인데요. 기본적으로 사용할 LLM 모델과, Graph 인스턴스가 파라미터로 들어가게 됩니다.
LLM 파라미터로 들어간 ChatOpenAI 는 OpenAI에서 제공하는 model 을 불러오기 위한 API[6]입니다. gpt-3.5-turbo 모델이 default 이며, OpenAI API Key가 필요합니다. (코랩 코드 참조)
(참조) ChatOpenAI 사용법
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0,
max_tokens=2048,
model_name='gpt-3.5-turbo',
)
question = 'ChatGPT가 뭐야?'
print(llm.predict(question))ChatGPT는 OpenAI가 개발한 자연어 처리 기술을 기반으로 한 대화형 인공지능 챗봇입니다. ChatGPT는 사용자와 자연스럽게 대화하며 질문에 답변하고 다양한 주제에 대해 이야기할 수 있습니다. 이러한 챗봇은 온라인 상에서 고객 서비스, 정보 제공, 엔터테인먼트 등 다양한 용도로 활용될 수 있습니다.
다시 돌아와서, GraphCypherQAChain 객체를 만들어줬었습니다. run 메소드를 통해 사용자 question 과 함께 바로 GraphRAG를 실현할 수 있습니다.
chain.run("Who played in Top Gun?")[output] Val Kilmer, Meg Ryan, Tom Skerritt, Kelly McGillis, Tom Cruise, Anthony Edwards played in Top Gun.
먼저, Top Gun 영화에 누가 등장하는 지를 물어보았는데요. 영화의 제목(title)을 'Top Gun'으로 제한해주고, 이 때 이 영화에 등장한 (ACTED_IN relationship) 사람을 p 로 받아와 Name을 출력하도록하는 Cypher문이 생성되었습니다. 실행결과 총 6명의 사람 이름이 도출되었고, 이 배우들의 이름을 답변해주고 있습니다.
chain.run("How many people played in Top Gun?")[output] 6 people played in Top Gun.
이번에는 Top Gun 영화에 몇명이 등장하는 지를 물어보았는데요. 명수를 물어보았기 때문에 COUNT 함수를 사용해주고 있습니다.
이렇게, 기대했던 대로 사용자의 질문을 이해한 Cypher 문을 생성해주고, 생성한 Cypher 쿼리의 결과 (Full context)를 토대로 답변을 내어주는 모습입니다.
[6] LangChain ChatOpenAI
: https://python.langchain.com/docs/integrations/chat/openai
Kaggle Amazon Fine Food Reviews 데이터셋으로 GraphRAG 구현하기
이제 그럼, Neo4j에서 제공하는 데이터셋이 아닌 외부 데이터셋으로 GraphRAG를 구현하며 마무리해보겠습니다.
https://www.kaggle.com/datasets/snap/amazon-fine-food-reviews/data
Amazon Fine Food Reviews
Analyze ~500,000 food reviews from Amazon
www.kaggle.com
위 데이터셋은 Amazon 의 Fine Food들에 대한 리뷰 데이터셋입니다. 2012년 10월까지의 약 50만개 리뷰를 포함하고 있으며, 10년 이상의 기간에 걸쳐 수집되었다고 합니다.
제공되는 Reviews.csv 데이터셋에는 각 row를 구분하는 Id 부터 시작해, 아래의 컬럼들을 가지고 있습니다.
- 상품의 Id (ProductId)
- 사용자 Id (UserId)
- 사용자 프로필이름 (ProfileName)
- 리뷰가 도움이 된 사람들의 수 (HelpfulnessNumerator)
- 리뷰가 도움이 되었는지에 대한 답변을 한 사람들의 수 (HelpfulnessDenominator)
- 상품에 대한 1점~5점 사이의 점수 (Score)
- 리뷰를 등록한 시점 (Time)
- 리뷰 요약 (Summary)
- 리뷰 텍스트 (Text)
사용자들이 매긴 리뷰 각각을 식별하는 ID와 함께 데이터를 확인할 수 있습니다.
이 데이터셋을 Knowledge Graph로 구축해보려 하는데요. 앞에서 사용했던 Neo4j Sandbox에서 이번에는 <Blank Sandbox>를 선택해주면 됩니다. 아래 설명 처럼, 본인의 CSV 데이터셋 임포팅을 통해 Graph DB 적재가 가능하다고 되어있네요.
📌 CSV Dataset Importing 하기
데이터 임포팅은 neo4j의 data-importer 를 활용했습니다. 아래 링크를 통해 접속이 가능합니다.
https://data-importer.neo4j.io/versions/0.7.0/
Neo4j Workspace
data-importer.neo4j.io
사이트에 들어가면 이런 화면을 확인할 수 있는데요. 중앙 상단에 <No connection>은 현재 Graph DB와 연결되어 있지 않다는 뜻입니다. 따라서 클릭하여 DB 정보를 입력해주셔야 합니다.
DB 정보는 Sandbox 상에서 확인할 수 있었습니다. 우리가 필요한 것은 하단에 Websocket Bolt URL 입니다. 해당 URL을 그대로 복사하여 붙여넣어주시면 됩니다. Username과 Password도 당연히 필요하겠죠!
연결을 해주었다면 왼쪽 상단에 보이는 +Add files 버튼을 눌러 사용하고자 하는 CSV 파일을 업로드 해주시면 됩니다. 저는 Reviews.csv 를 업로드 했고, 업로드 하면 간단히 어떤 컬럼을 가지고 있는 데이터인지, 샘플데이터와 함께 좌측에서 확인할 수 있습니다.
Amazon Fine Food Reviews 데이터 같은 경우, 크게 세가지의 노드로 만들 수 있었습니다. 사용자 정보를 담는 User, 상품의 정보를 담는 Product, 리뷰 정보를 담는 Review입니다.
그리고 Product는 해당상품을 구매한 사용자 정보와 연결되는 customer라는 관계를, User는 어떤 리뷰를 작성했는 지를 연결하는 write 관계를 생성하였으며, 상품은 어떤 리뷰들을 가지고 있는 지를 확인할 수 있도록 Review와 연결되는 review 관계를 연결해주었습니다.
노드들의 Property 까지 설정해주었다면, 화면 상단의 Run Import 버튼을 눌러 데이터 임포팅을 시작합니다!
임포팅이 완료되었네요. Graph DB에 데이터가 성공적으로 적재되었습니다.
📌 GraphRAG 질의응답 테스트
구축한 GraphDB를 통해 몇가지 질문을 던져, 제대로 검색하여 답변을 잘 생성해내는 지 확인해 보았습니다.
MATCH (p:Product)-->(u:UserId)-->(r:Review)
WHERE p.ProductId = 'B000EPP56U'
RETURN p,u,r LIMIT 100
먼저, 구축한 Graph DB를 통해 검색하면 이런 느낌인데요. 저는 B000EPP56U 라는 ID를 가진 상품에 대해 어떤 사용자들이 리뷰를 남겼고, 또 그 사용자가 어떤 리뷰들을 남겼는 지를 확인하는 쿼리문으로 시각화를 먼저 진행해보았습니다. 사용자와 상품, 리뷰들이 얽혀 시각화 된 것을 확인할 수 있습니다. 그럼 이 복잡한 관계를 지닌 데이터셋에서 원하는 정보만 빼서 질의해보아야겠죠.
1. 데이터 집계에 대한 질의
기본적으로, 구축한 Graph DB에 데이터들이 어떻게 저장되어있는 지 집계와 관련한 질의들을 몇가지 해보았습니다. 먼저, B000EPP56U 상품은 몇개의 리뷰를 가지고 있는 지 질문해보았는데요. 아래와 같은 cypher 쿼리문을 생성해냈습니다.
MATCH (:Product {ProductId: 'B000EPP56U'})-[:review]->(r:Review)
RETURN COUNT(r) as NumberOfReviews;
ProductId가 B000EPP56U 인 Product가 review라는 관계를 가지는 Review 노드를 몇개 가지고 있는지, 그 Review 노드를 r 이라고 했을 때 COUNT(r)을 하여 노드의 개수를 세는 쿼리문을 완벽히 작성해냈습니다.
실제로 neo4j desktop을 통해 결과를 확인한 결과, 15개라는 결과를 얻을 수 있었고, 해당 결과를 통해 LLM에게 'The B000EPP56U product has 15 reviews.' 라는 답변을 얻을 수 있었습니다.
비슷하게, Kerri Cherry 라는 사용자가 몇개의 리뷰를 썼는 지를 물어보았습니다. 마찬가지로 ProfileName이 Kerri Cherry 인 사용자가 Review 노드를 몇개 가지고 있는 지를 검색하는 Cypher 쿼리문을 잘 생성하였습니다.
결과가 1이기 때문에 'User Kerri Cherry has written 1 review.' 라는 답변을 얻었습니다.
이번에는 B000EPP56U 상품이 평균 몇점을 가지고 있는 지를 물어보았는데요. 각 리뷰는 텍스트 뿐 아니라 Score라고 하는 1점부터 5점까지의 평점 정보가 있었습니다. 생성된 Cypher 문을 보니 우선 B000EPP56U 상품이 가지고 있는 리뷰를 모두 찾아, 해당 리뷰의 Score property의 평균을 구하기 위해 AVG 함수를 사용해주었습니다.
실제로 쿼리문을 날려본 결과 4.6 점이라는 평균 평점을 확인할 수 있었고 이 결과를 토대로 LLM은 'The average score for the B000EPP56U product is 4.6.' 이라는 답변을 도출했습니다.
실제로 시각화도 해보았는데요, 검색된 노드들의 평점 평균들을 직접 계산기를 통해 확인해보았는데.. 4.6점이 맞았습니다. ㅎㅎ
2. 데이터 활용에 대한 질의
이번에는 단순히 검색을 통해 알 수 있는 집계에 대한 질의가 아닌, 검색된 데이터로 LLM에 좀 더 책임이 있는 질문들을 해보려 합니다.
먼저, B000EPP56U 상품의 리뷰들을 요약하게 했습니다. 생성된 Cypher 문을 보니 리뷰 노드의 Summary와 Text Property를 불러왔고, 두 Property는 리뷰의 요약 텍스트와, 전체 텍스트 입니다. 이제 이 결과를 기반으로 이후에는 LLM이 리뷰의 요약을 하여 적절한 답변을 내어주었습니다.
'The review text for the B000EPP56U product includes positive feedback about the taste, crunchiness, and health benefits of the crackers. Customers enjoy them as a snack and appreciate the variety of flavors available.'
실제로 리뷰 텍스트에 있던 내용들을 기반으로 요약을 해주는 것을 확인할 수 있었습니다.
다음은 5점인 리뷰가 가장 많은 상품은 어떤 것인지, 즉 가장 만족도가 높은 상품은 무엇인지에 대해 질문해보았습니다. 생성된 cypher문을 확인하면, WHERE절을 통해 Score 를 5로 제한하고, Review 노드의 카운팅을 통해 개수가 많은 순대로 정렬하여, 가장 상단의 상품 정보를 얻어왔습니다.
쿼리 실행 결과 B007JFMH8M 이라는 상품이 가장 5점 리뷰를 많이 받았고, 최종적으로 ' B007JFMH8M has the most 5-score reviews.' 라는 답변을 얻을 수 있었습니다.
이번 포스팅에서는 LangChain과 Neo4j를 활용한 기본적인 GraphQA 구현부터, 캐글 데이터셋을 직접 임포팅해 나만의 GraphRAG를 구현해보았습니다. LangChain과 함께라면 뭐든 할 수 있겠다는 걸 또 느낀 경험이었습니다. 앞으로는 얼마나 더 섬세한 데이터 저장과 검색이 가능해질 지 그 발전이 기대됩니다.
제가 실험한 코드는 아래 코랩을 통해 모두 확인 가능합니다. 감사합니다 😊
https://colab.research.google.com/drive/1kd0aNCEawk6PpQDpBRhf7rEPbGpROPXy?usp=sharing
GraphRAG - Own Dataset.ipynb
Colaboratory notebook
colab.research.google.com