
-
Knowledge Graph
-
Knowledge Graph for Recommender System
-
수학분야 학습자 역량 측정 데이터 - AIHub
-
Knowledge Graph 구축하기 (CSV to Neo4j)
-
1. 개념과 단원 관계 나타내기
-
2. 개념과 개념 간의 선후관계 연결하기
-
3. 문항정보와 학생정보, 정오답 표현하기
-
4. 문항정보와 학생정보, 정오답 + 각 문항이 속한 개념 관계 표현하기
-
Knowledge Recommender System by Cypher
-
1. A 개념의 기반 개념들 추천하기 (오답률 순 나열, 쉬운것부터)
-
2. A 문항과 같은 개념의 다른 문항 추천
-
3. A 문항을 틀린 사용자들이 틀린 문항 추천
Knowledge Graph
Knowledge Graph(지식 그래프)는 semantic network 라고도 알려져 있으며, 사물, 사건, 상황, 개념 등의 현실세계에서 다루어 지는 다양한 엔티티(Entity)들을 그들 간의 관계성(Relationship)과 함께 표현하는 그래프입니다. Knowledge Graph는 꽤 오래전부터 등장한 개념이지만, 최근 RAG(Retrieval-Augmented Generation) 방식으로 LLM(Large Language Model)을 사용하는 사례가 늘어나면서 지식 베이스 구조화의 중요성이 더욱 증대되고 있습니다. 특히 Graph 기반의 지식 저장 방식은 LLM 성능향상에 도움을 준다고 알려져 있습니다. GraphDB를 활용하면, 정보 간의 복잡한 관계를 구조화할 수 있고 이를 활용해 쿼리의 의도를 이해하고 정확한 정보를 찾기 용이해지기 때문인데요. 아무튼, 저 또한 세상의 흩어진 지식데이터들을 그래프 형태로 구조화하는 것의 중요성을 직접 적용해보기 위해 지식그래프 기반의 추천시스템을 구현해보려 합니다.
Knowledge Graph for Recommender System
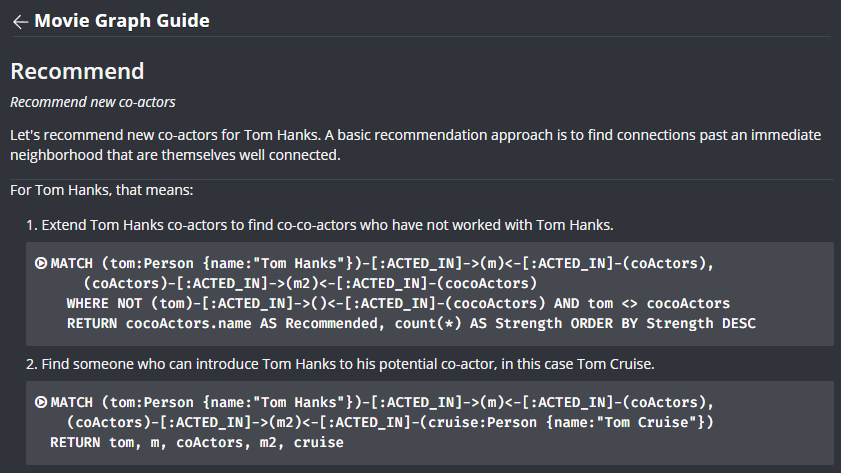
Graph 를 활용해 추천시스템은 어떤 식으로 구현될 수 있을까요? 위 그림은 Neo4j Movie Graph DBMS 가이드의 일부입니다. 영화 출연 배우와 감독, 영화 정보들의 관계를 표현한 그래프를 통해 어떤 추천을 할 수 있는 지 예시가 작성되어 있는데요. 기본적인 추천을 위한 접근방식은 인접하는 노드와 연결된 관계를 찾는 것이라 언급되어 있습니다. (A basic recommendation approach is to find connections past an immediate neighborhood that are themselves well connected.) 그래서 첫째로, 톰행크스 배우에게 동료를 추천하기 위해, 함께 촬영한 배우(coActors)와 함께 일한 또 다른 배우(cocoActors)를 찾아 추천해줍니다. 이웃을 찾아 그 이웃과 연결된 또 다른 누군가를 추천하는 것입니다. 둘째로는, 톰행크스와 함께 연기한 배우들 중 톰 크루즈가 출연한 영화에 등장한 적이 있는 배우를 추천합니다. 톰크루즈와 연결될 수 있는 중간다리역할의 배우를 찾기 위해서입니다. 이렇듯 이미 사람과 아이템 간의 관계가 지식그래프로 구조화되어 있기 때문에, 이를 활용한 추천 논리만 정의한다면 Cypher 쿼리문만으로 추천시스템 구현이 가능합니다.
이를 교육에 적용해보려 합니다. 교육, 학습에서는 학생들에게 수준별 문항을 추천하거나, 부족한 개념을 채워줄 학습콘텐츠를 추천해주어야 합니다. 크게 세가지 정도로 정의해보았습니다.
1. 기반 개념 추천
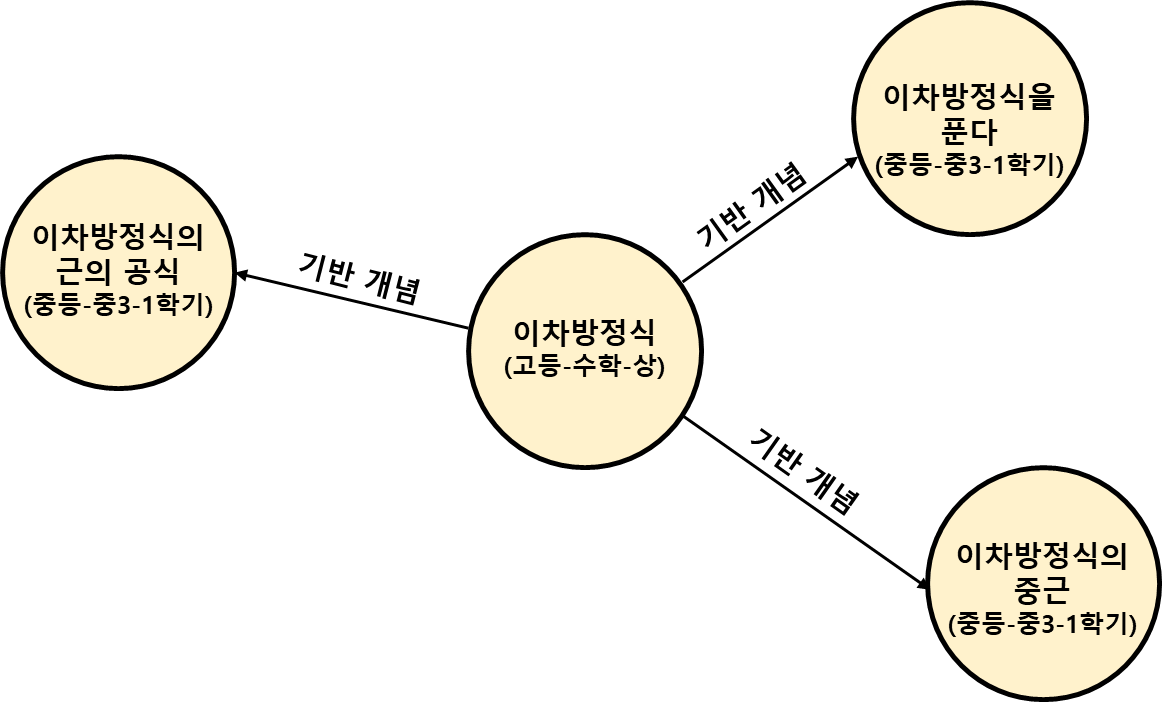
먼저, 개념학습이 필요한 학생에게는 선행학습보다는 기반학습이 중요할 수 있습니다. 위 그림은 고등 수학 상에 등장하는 '이차방정식'이라는 개념을 공부하기 위해서는 연결된 3가지의 기반 개념이 필요하다는 것을 나타낸 그래프라 할 수 있습니다. 보시다시피 중학교3학년에 등장하는 이차방정식에 관한 개념들을 알아야, 고등 수학 상에 등장하는 이차방정식 개념을 해결할 수 있다고 말하고 있네요.
이 경우에는, 만약 학생이 고등 수학-상의 이차방정식을 공부하고 있고 기본적인 문제를 해결하지 못하거나 개념 이해에 어려움을 겪고 있다면, 기반이 되는 중등 3학년 개념을 추천해주어, 복습하도록 유도할 수 있을 것입니다.
2. 문항 추천

다음은 문항추천입니다. 가장 흔히 시험을 대비하기 위해 수준에 맞는 문항을 추천하거나 풀었던 문제와 유사한 문항을 추천할 수 있을 것 같은데요. 위 그림은 노란색으로 표현된 각 개념과 관련한 여러 문제를 표현한 그래프입니다. 만약 학생이 '이차방정식을 푼다' 라는 개념의 문항 10번을 틀렸고, 그럼 이 사용자에게는 같은 개념의 문항을 더 연습해보라고 같은 개념의 다른 문항을 추천해줄 수 있을 것입니다.
3. 문항 추천 (사용자 기반)
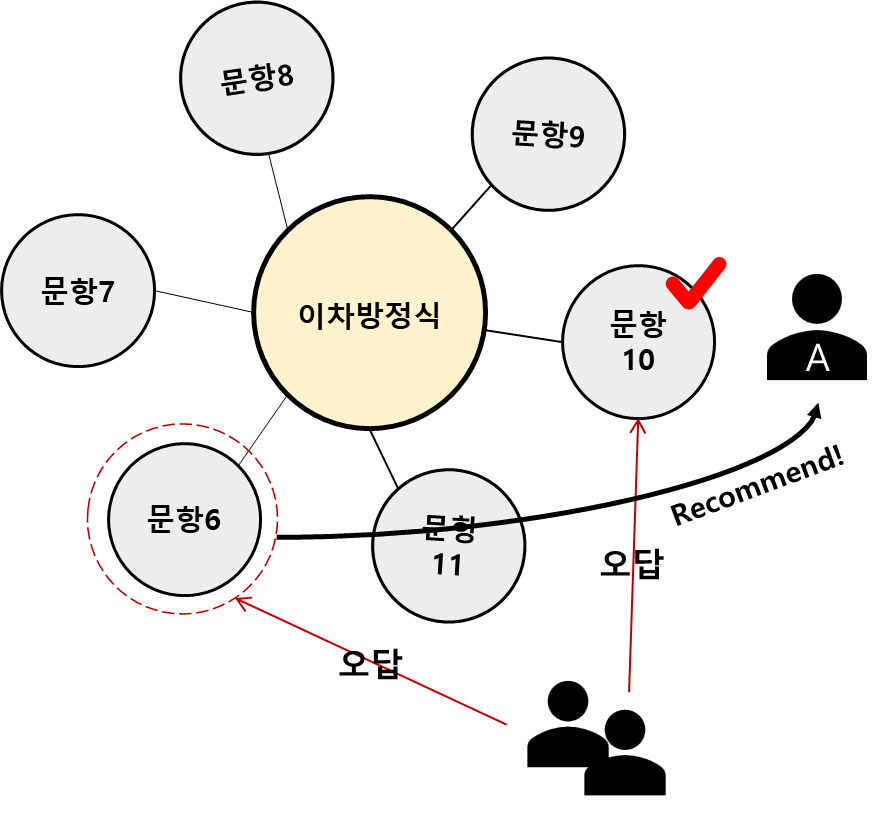
다음 추천 방식도 문항추천입니다. 직전의 문항추천과 다른점은 사용자 정보가 추가되었다는 점입니다. 이번에는 개념과 문항 정보 뿐만 아니라, 각 문항을 풀이한 모든 학생들의 정보까지 그래프로 표현해서, A 학생이 만약 문항 10번을 틀렸다면, 문항 10번을 틀린 다른 학생들이 많이 틀린 또 다른 문항인 6번을 A 학생에게 추천해주는 것입니다. 협업필터링과 유사하게, 사용자 행동데이터를 기반으로 유사한 아이템을 추천하겠다는 뜻이고, 여기서 행동데이터가 문항 정오답여부, 아이템이 문항이 된 것입니다. 쉽게 표현하면, "이 문항을 틀린 학생들은 또 이런 문항을 틀렸으니 함께 공부해보세요!" 정도로 정리해서 학생에게 보여줄 수 있겠네요.
위 세가지 정도의 학습 추천 시스템을 구현하기 위해서 우선 개념과 문항, 학생 정보를 표현한 지식그래프를 구축하고, Cypher 를 활용해 추천시스템을 간단히 구현해보려 합니다.
수학분야 학습자 역량 측정 데이터 - AIHub
https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=133
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
aihub.or.kr
제가 사용한 데이터는 AI 허브에 등록되어 있는 수학분야 학습자 역량 측정 데이터 입니다. 이전에 제가 해당 데이터셋에 대해 간단히 리뷰한 적이 있습니다. 참고바랍니다. https://uoahvu.tistory.com/entry/AIEd를-위한-학습풀이이력-공개데이터셋
해당 데이터에서 추천시스템 구현에 사용한 데이터셋은 아래와 같습니다.
1. 문항정오답표
{"learnerID": "A090000914", "learnerProfile": "M;S01;9", "testID": "A090000001", "assessmentItemID": "A090001001", "answerCode": "0", "Timestamp": "2021-05-30 11:56:11"}
학생(learner)별 문항(assessmentItem) 정오답(answerCode) 데이터
2. 문항IRT
{"testID": "A090000072", "assessmentItemID": "A090072006", "difficultyLevel": "0.8390383520999999", "discriminationLevel": "1.3322960958", "guessLevel": "0.0034785868", "Timestamp": "2020-12-24 01:01:46", "knowledgeTag": "2648"}
문항(assessmentItem)별 IRT(문항반응이론) 난이도(difficultyLevel), 변별도(discriminationLevel), 추측도(guessLevel) 데이터
3. 수학지식체계 데이터셋
"0": {
"fromConcept": {
"id": 3249,
"name": "거듭제곱",
"semester": "고등-수1-전체",
"description": "임의의 수 $a$와 양의 정수 $n$에 대하여 $a$를 $n$개 거듭하여 곱한 것을 $a$의 $n$제곱이라 하고 $a^n$으로 나타낸다. 또 $a,a^2,a^3,\\cdots,a^n,\\cdots$을 통틀어 $a$의 거듭제곱이라 한다.",
"chapter": {
"id": "587",
"name": "지수함수와 로그함수 > 지수 > 거듭제곱과 거듭제곱근"
},
"achievement": {
"id": "314",
"name": "거듭제곱과 거듭제곱근의 뜻을 알고, 그 성질을 설명할 수 있다."
}
},
"toConcept": {
"id": 1442,
"name": "거듭제곱",
"semester": "중등-중2-1학기",
"description": "같은 수나 문자를 거듭하여 곱한 것을 간단히 나타낸 것",
"chapter": {
"id": "481",
"name": "식의 계산 > 단항식의 계산 > 지수법칙"
},
"achievement": {
"id": "88",
"name": "지수법칙을 이해한다."
}
}
},
수학 교육과정 간의 지식체계를 나타낸 데이터
기준개념(fromConcept)의 선행개념(toConcept)의 메타정보 데이터
Knowledge Graph 구축하기 (CSV to Neo4j)
학습 추천 시스템 구현을 위해 Knowledge Graph를 구축하기 위해, Neo4j를 활용할 예정입니다. Neo4j는 그래프 데이터베이스 DBMS이며, Cypher라고 하는 그래프 쿼리 언어를 통해 그래프 데이터를 다룰 수 있습니다.
위에서 소개한 수학역량데이터셋은 모두 json 파일의 데이터들이며, 저는 이 json 형태의 데이터셋을 컨셉별로 csv 데이터로 생성했고, 생성한 데이터는 아래와 같습니다.
- concept csv : 개념 데이터
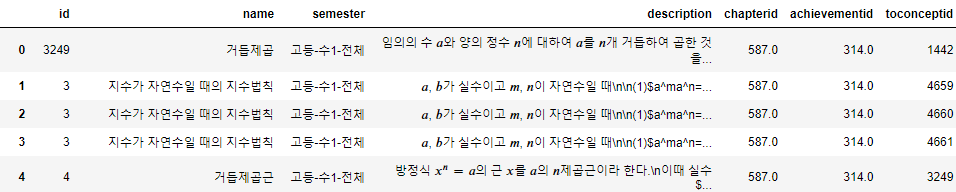
<3. 수학지식체계 데이터셋>에서 추출한 개념 메타정보이며, "toconceptid" 컬럼으로 toConcept 키 데이터를 추가했습니다.
- chapter.csv : 단원 데이터
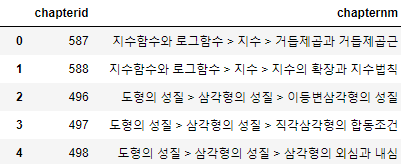
<3. 수학지식체계 데이터셋>에서 추출한 Chapter 메타정보 ID에 맵핑되는 Chapter name 테이블입니다.
- correct.csv : 정오답 데이터

<1. 문항정오답표> 에서 추출한 학생(learner)별 문항(assessmentItem) 정오답(answerCode)을 나타낸 테이블입니다.
- problem.csv : 문항 데이터
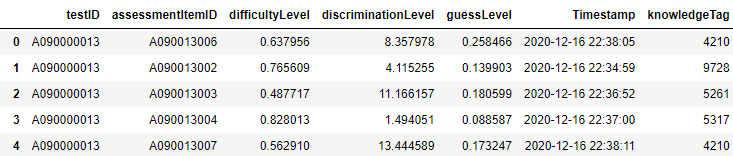
<2. 문항IRT> 데이터에서 추출한 각 문항(assessment)의 IRT 정보가 들어있는 테이블입니다. "knowledgeTag" 컬럼의 아이디정보는 concept.csv 의 id와 맵핑됩니다.
그렇다면, 이 CSV 파일들을 가지고 Knowledge Graph를 구축해보겠습니다. Graph를 구축하기 위한 Cypher 기본 문법은 Cypher 공식 docs를 참고했습니다. :) https://neo4j.com/docs/cypher-manual/current/introduction/
Introduction - Cypher Manual
This section provides an introduction to the Cypher query language.
neo4j.com
1. 개념과 단원 관계 나타내기
먼저, KnowledgTag 혹은 Concept 이라 불리는 학습 개념과, Chapter 즉 단원을 노드로 생성하고, 이 학습개념(Concept)들이 어떤 단원(Chapter)에 속하는 지 표현해보겠습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load Concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept.csv' AS row
MERGE (c:Concept {id: row.id, name: row.name})
RETURN count(c);
// load Chapter nodes
LOAD CSV WITH HEADERS FROM 'file:///chapter.csv' AS row
MERGE (h:Chapter {id: row.chapterid, name: row.chapternm})
RETURN count(h);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///concept.csv' AS row
MATCH (c:Concept {id: row.id})
MATCH (h:Chapter {id: row.chapterid})
MERGE (c)-[:BELONGS_TO]->(h)
RETURN *;
생성해주었던 concept.csv 에서 학습개념(concept)의 id, name을 노드 property로 불러왔습니다. 단원(Chapter) 정보도 함께 표현해줄 것이기 때문에 chapter.csv 에서 chapterid, chapternm을 불러와 노드로 생성해줍니다. 생성된 학습개념과 단원 노드를 연결하는 관계(relationships)는 [BELONGS_TO]라는 이름으로 정의하여, 각 학습개념이 어떤 단원에 속하는 지를 연결해주었습니다.
MATCH (n:Concept)-[r]-(m:Chapter)
RETURN n, r, m

학습개념은 베이지색 노드, 단원은 핑크색 노드로 표현되었고, 각 학습개념이 어떤 단원에 속해있는 지 확인할 수 있습니다. 하나의 단원에는 여러 개념들이 포함되어 있기 때문에 단원의 노드 크기를 크게 하여 포함관계를 시각화했습니다.
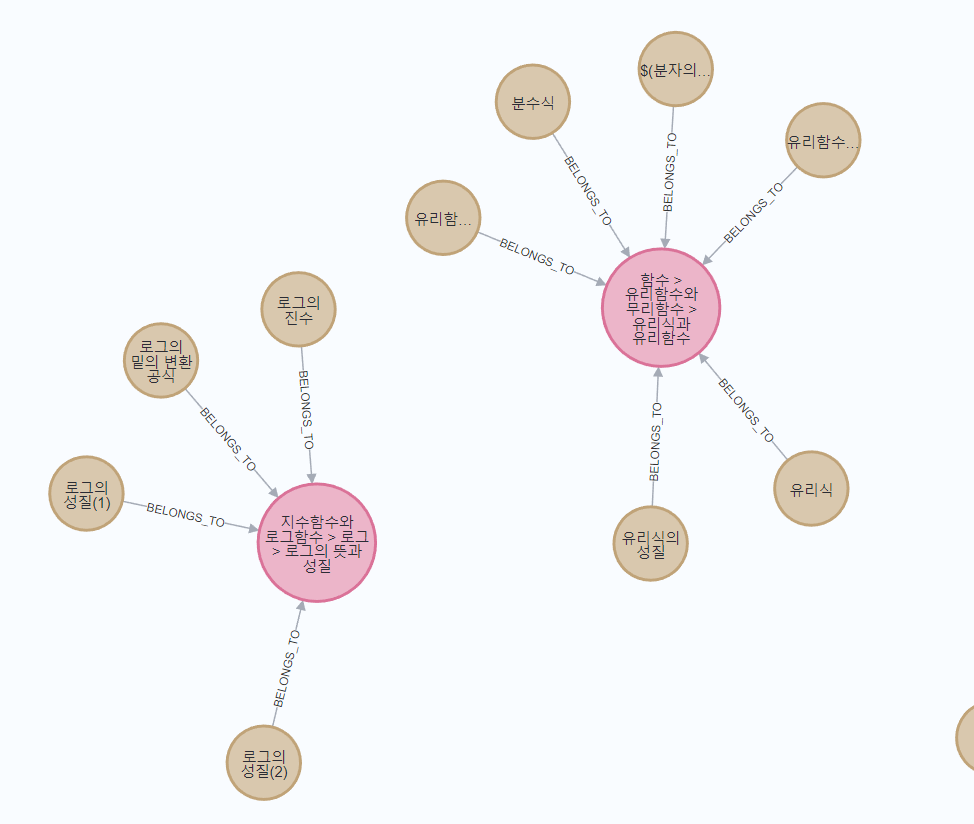
확대해 살펴보면 위 그림처럼 어떤 단원에 어떤 학습개념들이 포함되어 있는 지 확인할 수 있습니다.
2. 개념과 개념 간의 선후관계 연결하기
사용했던 데이터셋은 수학지식체계 즉, 개념간의 선후관계가 표현되어 있던 데이터 였습니다. 그래서 학습 개념이 어떤 단원에 속해있는 지 뿐 아니라, 각 학습개념들이 또 어떤 학습개념과 연계되는 지를 알 수 있었는데요. 따라서 concept과 concept 노드 간의 관계를 하나 더 추가해서, 연계되는 학습개념을 확인할 수 있도록 해보겠습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load Concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept.csv' AS row
MERGE (c:Concept {id: row.id, name: row.name, semester: row.semester, description: row.description})
RETURN count(c);
// load Chapter nodes
LOAD CSV WITH HEADERS FROM 'file:///chapter.csv' AS row
MERGE (h:Chapter {id: row.chapterid, name: row.chapternm})
RETURN count(h);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///concept.csv' AS row
MATCH (c:Concept {id: row.id})
MATCH (h:Chapter {id: row.chapterid})
MERGE (c)-[:BELONGS_TO]->(h)
RETURN *;
// create (linkage concept) relationships
LOAD CSV WITH HEADERS FROM 'file:///concept.csv' AS row
MATCH (c:Concept {id: row.id})
MATCH (tc:Concept {id: row.toconceptid})
MERGE (c)-[:BASED_IN]->(tc)
RETURN *;
나머지는 동일하고, 가장 마지막에 concept 사이의 관계를 정의하는 쿼리만 추가되었습니다. [BASED_IN] 이라는 관계를 정의하여, concept.csv에서 id와 toconceptid 컬럼이 연결될 수 있도록 구현했습니다. 이를 통해 기준이 되는 학습개념(c:Concept)이 어떤 학습개념(tc:Concept)과 연계되는 지를 표현했습니다.
MATCH (fc:Concept)-[r1]-(tc:Concept)-[r2]-(m:Chapter)
RETURN fc, r1, tc, r2, m
fromconcept과 toconcept 노드를 연결하고, toconcept이 어떤 단원에 속하는 지 표현해주었습니다. 1번에서는 단원별로 노드들이 동떨어져 있었다면, 이번에는 개념끼리의 연계관계까지 포함되었기 때문에 엣지들이 얽힌 모습을 확인할 수 있습니다.
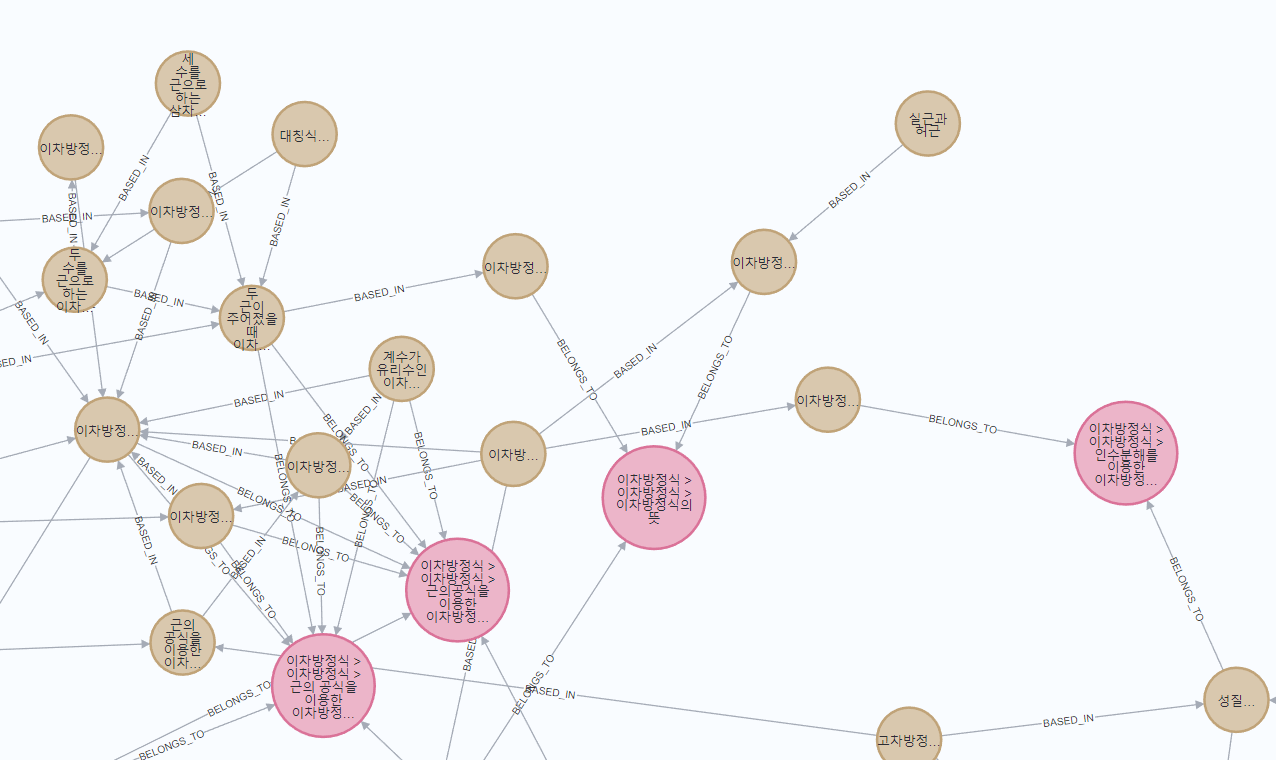
BASED_IN 관계 엣지가 도착하는 방향에 있는 노드가, 출발한 노드의 기반이 되는 학습개념이라는 뜻입니다.


하나를 확대해서 볼까요? <급수의 발산>이라는 학습 개념은 <발산> 이라는 학습개념에 기반한다고 표현되어 있습니다. 각 노드의 property의 semester 메타를 보면 알다시피, 수2에서 <발산> 개념을 먼저 배운 후에 미적 과목에서 <급수의 발산>을 배우게 됨을 확인할 수 있네요.
3. 문항정보와 학생정보, 정오답 표현하기
이제는 학생 정보까지 추가해보려 합니다. 결국 우리는 문항 추천까지 구현해야 하고, 그러기 위해서는 학생들이 어떤 문항을 맞혔는 지, 각 학습개념에는 어떤 문항들이 존재하는 지를 알아야 합니다. 따라서 이번에는 아까 만들어 주었던 CSV 중 문항 정보가 들어있던 problem.csv 과 학생별 문항 정오답 이력이 들어있던 correct.csv를 사용합니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load students nodes
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MERGE (s:Student {id: row.learnerID, profile: row.learnerProfile})
RETURN count(s);
// load problem nodes
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MERGE (p:Problem {id: row.assessmentItemID, difficulty: row.difficultyLevel, kt: row.knowledgeTag})
RETURN count(p);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MATCH (s:Student {id: row.learnerID})
MATCH (p:Problem {id: row.assessmentItemID})
MERGE (s)-[:SOLVED{correct: row.answerCode}]->(p)
RETURN *;
correct.csv에서 학생 정보를 불러와 Student 노드로 정의했고, problem.csv 에서 문항 정보 중 난이도, 학습개념 정보를 불러와 Problem 노드를 구성했습니다. 그리고 각 학생들이 어떤 문제를 풀었는 지, 그 문제를 맞혔는 지 틀렸는 지를 [SOLVED] 로 표현했고 정오답 여부를 해당 관계 엣지의 property 로 구성했습니다.
MATCH (s:Student)-[c]->(p:Problem)
RETURN s, c, p
LIMIT 100
모든 문항 풀이이력을 불러오면 매우 많아져서, 100쌍의 관계만 출력하도록 LIMIT를 걸었습니다.
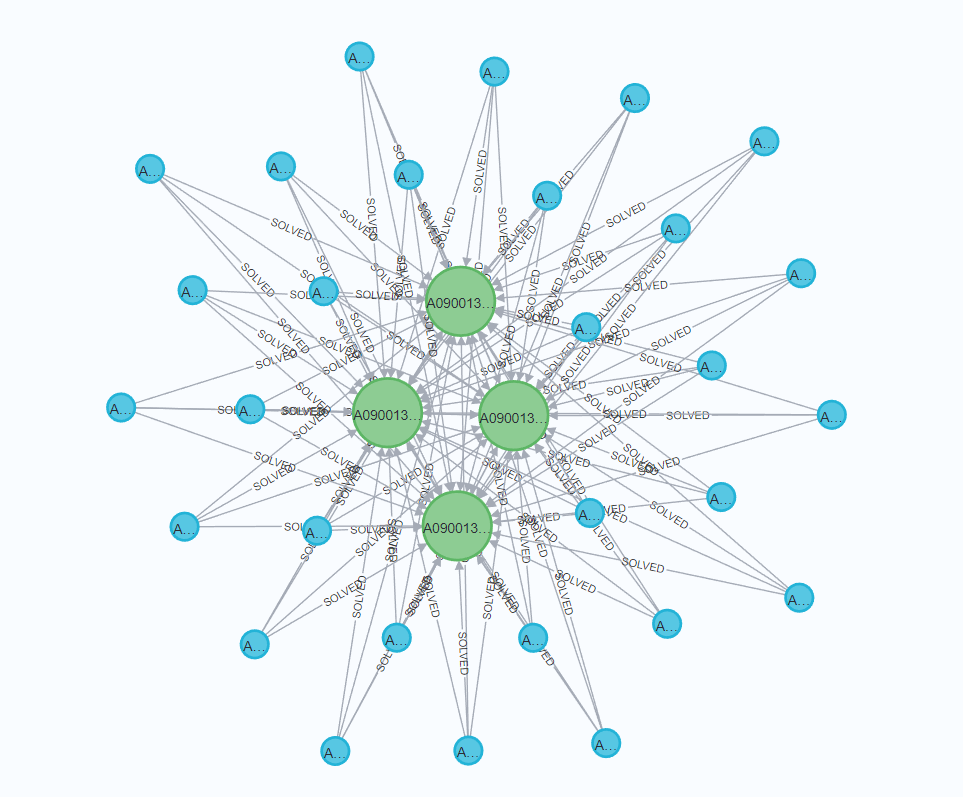
초록색으로 표현한 노드는 문항, 파란색 노드는 학생 노드입니다. 4개의 문항에 대해 29명의 학생들이 풀이하였음을 확인할 수 있습니다.
4. 문항정보와 학생정보, 정오답 + 각 문항이 속한 개념 관계 표현하기
그럼 더 나아가, 처음에 개념과 단원 정보를 표현했던 것처럼, 각 문항에 대한 개념, 단원 정보가 들어가면 더더욱 좋을 것 같습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MERGE (c:Concept {id:row.id, name:row.name, incorrectRate:row.answerCode})
RETURN count(c);
// load students nodes
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MERGE (s:Student {id: row.learnerID, profile: row.learnerProfile})
RETURN count(s);
// load problem nodes
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MERGE (p:Problem {id: row.assessmentItemID, difficulty: row.difficultyLevel, kt: row.knowledgeTag})
RETURN count(p);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MATCH (s:Student {id: row.learnerID})
MATCH (p:Problem {id: row.assessmentItemID})
MERGE (s)-[:SOLVED{correct: row.answerCode}]->(p)
RETURN *;
// create relationships(kt)
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MATCH (p:Problem {kt: row.knowledgeTag})
MATCH (c:Concept {id: row.knowledgeTag})
MERGE (p)-[:knowledge]->(c)
RETURN *;
제가 분석에 사용한 문항 풀이이력이 중학교 3학년 학생들의 이력이라, concept.csv을 그대로 사용하지 않고 중학교 3학년에 해당하는 학습개념만 가져와 사용했습니다. 직전과 달라진 점은, knowledge 라는 관계를 추가하여, 각 문항이 어떤 Concept(학습개념)에 해당하는 지를 표현한 관계를 추가해주었습니다. 또한, 개념(Concept) 노드의 property로 incorrectRate 이라는 메타를 추가하였는데요, 사용한 문항풀이이력을 가지고 concept별 오답률을 계산해 추가해주었습니다. 이는 뒤에는 추천 시스템 구현에 활용할 예정입니다!
MATCH (s:Student)-[r]->(p:Problem)-[k]->(c:Concept)
RETURN s, r, p, k, c
LIMIT 100
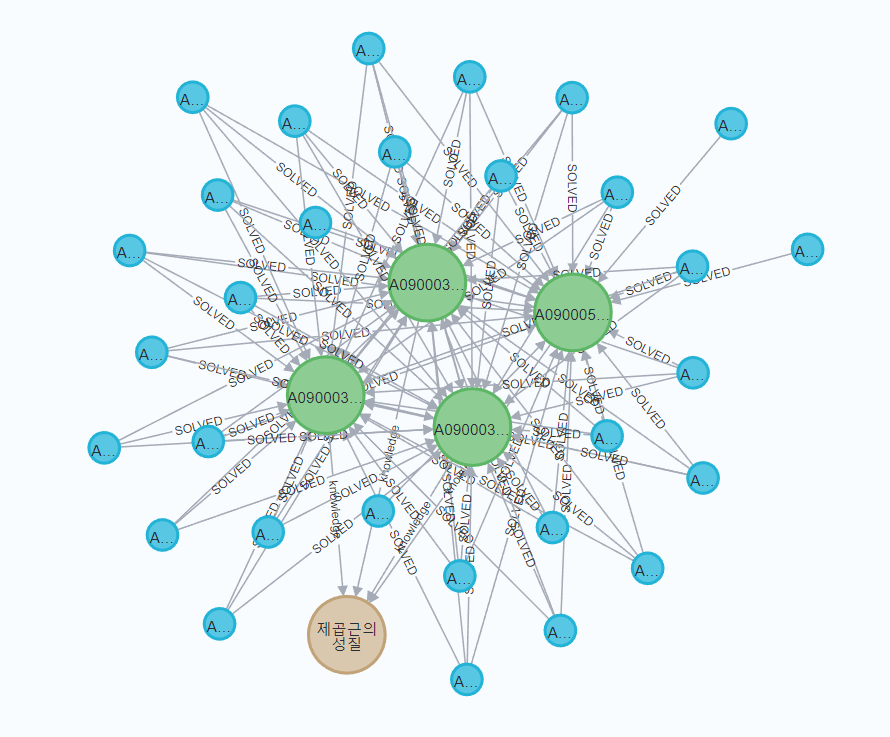
결과를 출력해보면, 학생, 문항 정보 외에 베이지색 노드로 개념 노드가 추가된 것을 확인할 수 있습니다.
여기까지 하면 기본적인 학습개념과 단원의 정보 표현부터, 학생정보와 정오답 이력까지 Graph로 표현해보았습니다. 이렇게 구축해본 Knowledge Graph를 기반으로 추천시스템을 본격적으로 구현해보려 합니다.
Knowledge Recommender System by Cypher
제가 위에서, 학습 추천에서 가능한 추천 3가지 정도를 구상해보았었습니다. 크게 기반개념추천, 문항추천이 있었는데요. 앞에서 구축한 Knowledge Graph를 기반으로 Cypher 쿼리언어를 사용해 간단히 추천시스템을 구현해보았습니다.
1. A 개념의 기반 개념들 추천하기 (오답률 순 나열, 쉬운것부터)
먼저, 개념공부가 부족한 학생을 위해 약한 학습개념의 기반이 되는 학습개념을 추천해볼 수 있습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load Concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MERGE (c:Concept {id: row.id, name: row.name, incorrectRate:row.answerCode, semester: row.semester, description: row.description})
RETURN count(c);
// load Chapter nodes
LOAD CSV WITH HEADERS FROM 'file:///chapter.csv' AS row
MERGE (h:Chapter {id: row.chapterid, name: row.chapternm})
RETURN count(h);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MATCH (c:Concept {id: row.id})
MATCH (h:Chapter {id: row.chapterid})
MERGE (c)-[:BELONGS_TO]->(h)
RETURN *;
// create (linkage concept) relationships
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MATCH (c:Concept {id: row.id})
MATCH (tc:Concept {id: row.toconceptid})
MERGE (c)-[:BASED_IN]->(tc)
RETURN *;
중학교 3학년에 등장하는 개념(KnowledgeTag) 정보가 들어간 데이터로 구축한 "2. 개념과 개념 간의 선후관계 연결하기"
지식그래프를 불러왔습니다.
MATCH (fromc:Concept {name:"복잡한 이차방정식을 푸는 방법"})-[:BASED_IN]->(tc)
RETURN tc.name, tc.incorrectRate AS i ORDER BY i ASC
"복잡한 이차방정식을 푸는 방법" 이라는 name을 가진 Concept 노드(fromc)와, 해당 노드와 연결(:BASED_IN)되는 기반 학습개념 노드(tc)를 불러오고 기반학습개념의 name와 오답률을 기준으로 정렬해 출력해보았습니다. 그래프 구조로 쉽게 찾은 기반 학습개념과 관련한 콘텐츠를 바로 추천해주거나, 오답률이 낮은 학습개념부터 차근히 추천해볼 수도 있겠네요.
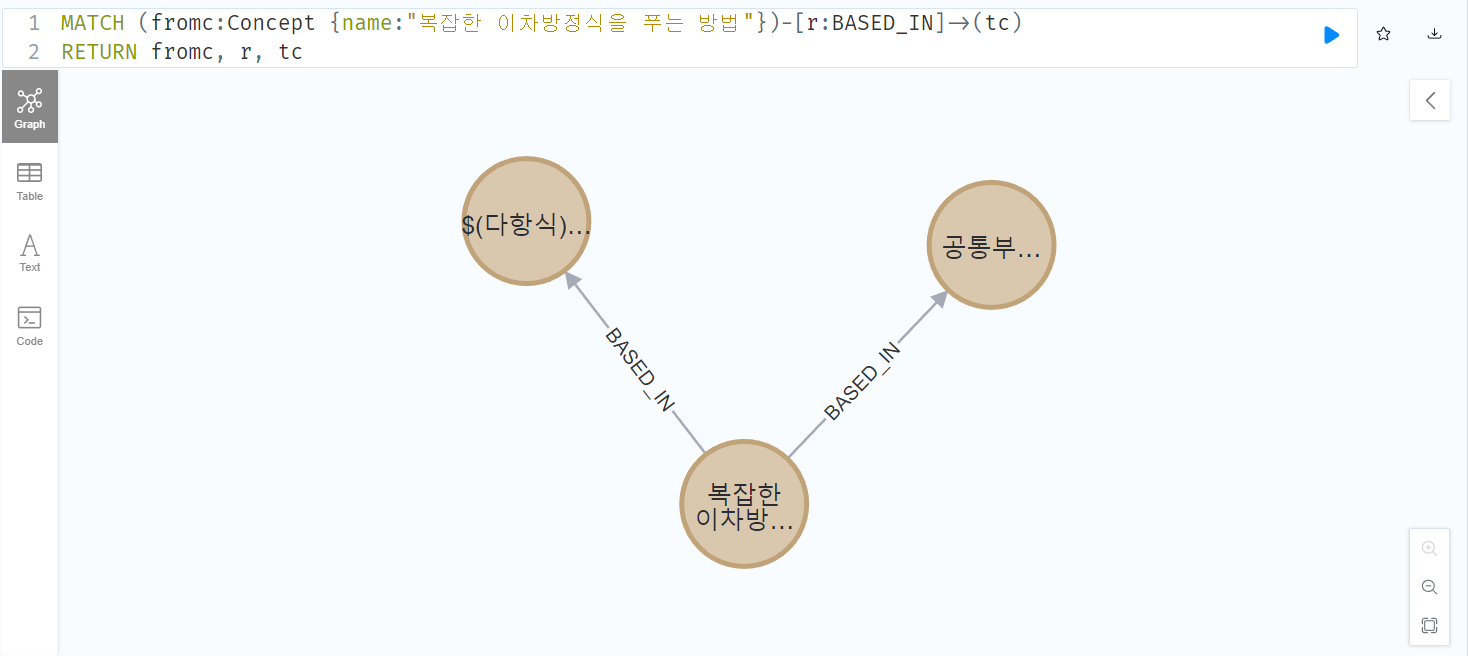
2. A 문항과 같은 개념의 다른 문항 추천
다음은 문항추천입니다. 위에서 문항 추천을 두가지로 나누었었는데, 그 중 같은 개념에 속하는 다른 문항을 추천하겠다는 내용입니다. 만약 어떤 학생이 A라는 개념을 틀렸다면, A 개념에 속하는 또 다른 문제들을 계속 추천해줌으로서 학생이 A개념을 보완할 수 있도록 도울 수 있습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MERGE (c:Concept {id:row.id, name:row.name, incorrectRate:row.answerCode})
RETURN count(c);
// load students nodes
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MERGE (s:Student {id: row.learnerID, profile: row.learnerProfile})
RETURN count(s);
// load problem nodes
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MERGE (p:Problem {id: row.assessmentItemID, difficulty: row.difficultyLevel, kt: row.knowledgeTag})
RETURN count(p);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MATCH (s:Student {id: row.learnerID})
MATCH (p:Problem {id: row.assessmentItemID})
MERGE (s)-[:SOLVED{correct: row.answerCode}]->(p)
RETURN *;
// create relationships(kt)
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MATCH (p:Problem {kt: row.knowledgeTag})
MATCH (c:Concept {id: row.knowledgeTag})
MERGE (p)-[:knowledge]->(c)
RETURN *;
이번에는 문항풀이이력을 기반으로 구축했던 문항, 학생 정보가 포함된 지식그래프를 불러왔습니다.

"인수분해" 라는 name 을 가진 Concept 에 속하는 문항들을 모두 불러온 모습입니다. 총 24개의 문항들이 인수분해 노드와 연결되었네요.
MATCH (p:Problem {id:"A090024003"})-[k]->(c)<-[a]-(otherproblem)
WHERE p <> otherproblem
RETURN otherproblem.id AS 추천문항ID, toFloat(otherproblem.difficulty) AS 추천문항난이도, toFloat(p.difficulty) AS 틀린문항난이도, (ABS(toFloat(otherproblem.difficulty) - toFloat(p.difficulty))) AS 틀린문항과의난이도차 ORDER BY 틀린문항과의난이도차 ASC
MATCH (p:Problem {id:"A090024003"})-[k]->(c)<-[a]-(otherproblem)
"인수분해" 개념에 속하는 문항 중 A090024003 이라는 ID를 가지는 문항을 기준으로 테스트해보았습니다. A090024003 문항(p)이 어떤 개념(c)에 속하는 지(k) 구하고, 해당 개념에 속하는(a) 또 다른 문항(otherproblem)을 불러와줍니다.
WHERE p <> otherproblem
이 때, 추천되는 문항은 사용자가 아직 풀이하지 않은 문항이어야 하므로, 기준이 되는 문항과 동일하지 않도록 WHERE 문을 걸어주었습니다.
(ABS(toFloat(otherproblem.difficulty) - toFloat(p.difficulty))) AS 틀린문항과의난이도차 ORDER BY 틀린문항과의난이도차 ASC
또, 풀이한 문항과 비슷한 난이도의 문항을 추천할 수 있도록 기준 문항과 추천문항 간의 난이도 차이가 적은 순서대로 정렬해 출력하도록 했습니다.
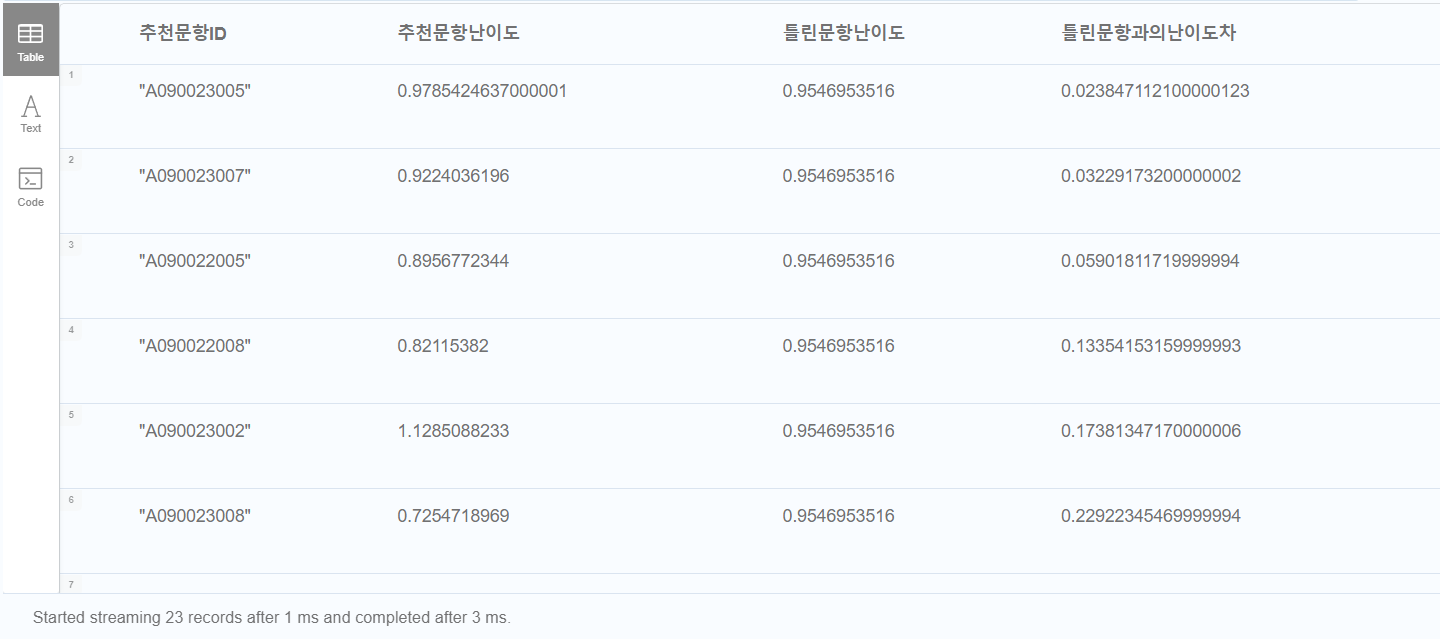
만약, 가장 난이도 차이가 적은 하나만 추천하고 싶다면 LIMIT 1 을 걸어주면 됩니다!
MATCH (p:Problem {id:"A090024003"})-[k]->(c)<-[a]-(otherproblem)
WHERE p <> otherproblem
RETURN otherproblem.id AS 추천문항ID, toFloat(otherproblem.difficulty) AS 추천문항난이도, toFloat(p.difficulty) AS 틀린문항난이도, (ABS(toFloat(otherproblem.difficulty) - toFloat(p.difficulty))) AS 틀린문항과의난이도차 ORDER BY 틀린문항과의난이도차 ASC
LIMIT 1

3. A 문항을 틀린 사용자들이 틀린 문항 추천
다음도 문항추천입니다. 다른 점은 사용자를 기반으로 추천한다는 것이었는데요. 만약 어떤 학생이 A문항을 틀렸다면, A문항을 틀린 다른 사용자들의 정보를 쭉 가져와서, 해당 사용자들이 또 많이 틀린 다른 문항을 추천해주는 것입니다. 다른 학생들이 틀린 문제를 해당 학생은 틀리지 않도록 대비하게 도와줄 수 있습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MERGE (c:Concept {id:row.id, name:row.name, incorrectRate:row.answerCode})
RETURN count(c);
// load students nodes
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MERGE (s:Student {id: row.learnerID, profile: row.learnerProfile})
RETURN count(s);
// load problem nodes
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MERGE (p:Problem {id: row.assessmentItemID, difficulty: row.difficultyLevel, kt: row.knowledgeTag})
RETURN count(p);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MATCH (s:Student {id: row.learnerID})
MATCH (p:Problem {id: row.assessmentItemID})
MERGE (s)-[:SOLVED{correct: row.answerCode}]->(p)
RETURN *;
// create relationships(kt)
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MATCH (p:Problem {kt: row.knowledgeTag})
MATCH (c:Concept {id: row.knowledgeTag})
MERGE (p)-[:knowledge]->(c)
RETURN *;
방금 사용한 지식그래프와 동일한 그래프를 사용합니다.
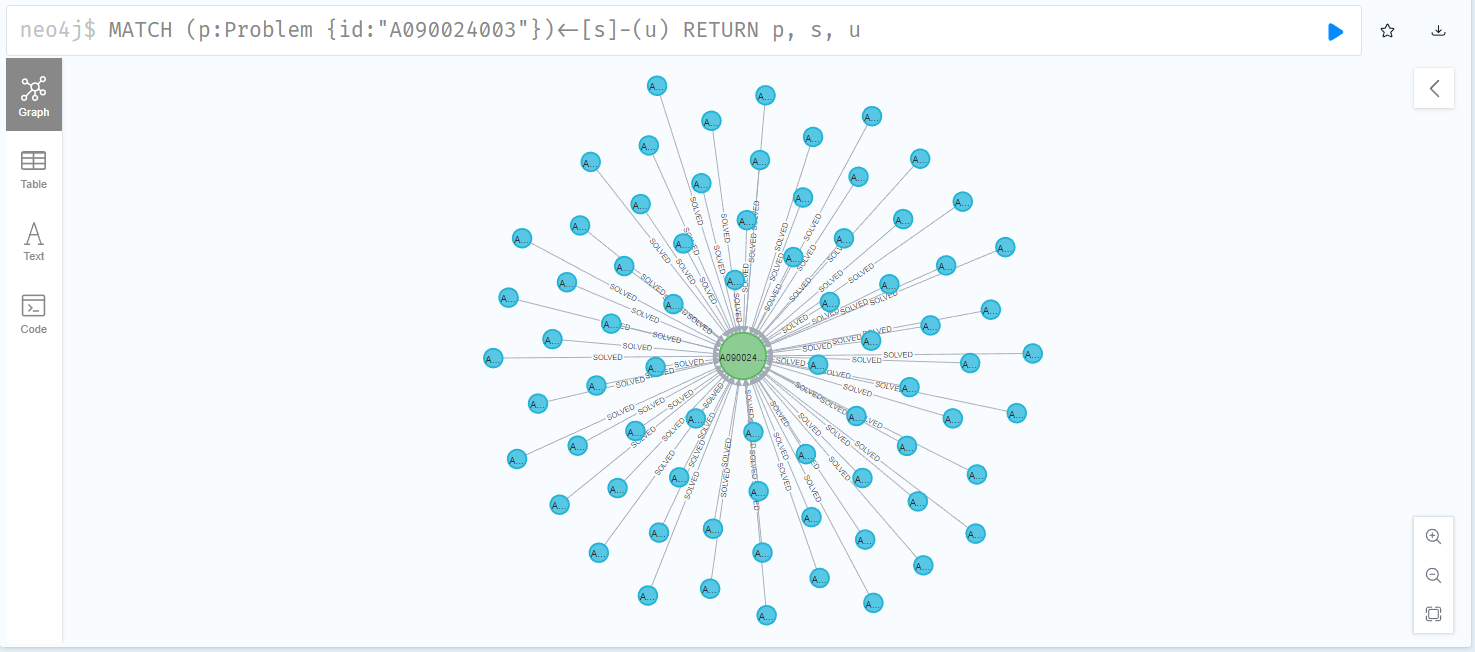
다만, 이번에는 A090024003 ID를 가진 문항(Problem) 을 풀이한(s) 사용자 정보(u)를 불러왔습니다.
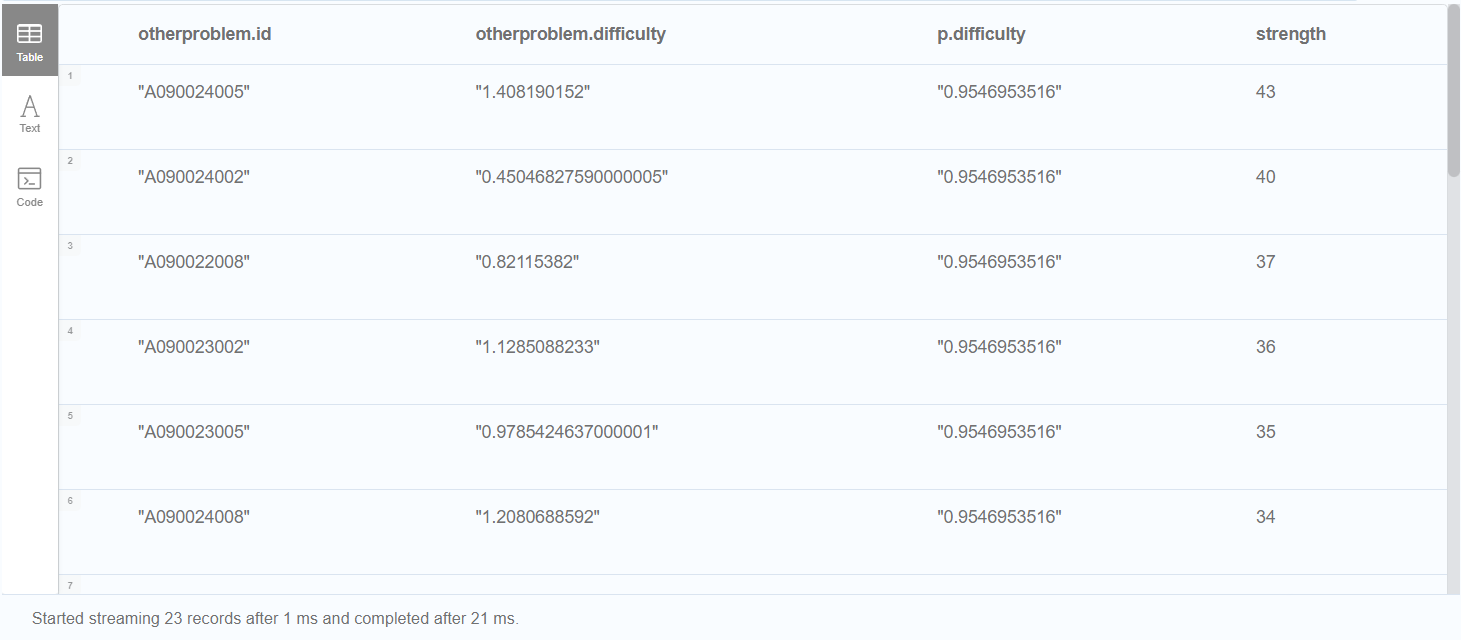
MATCH (p:Problem {id:"A090024003"})<-[s1:SOLVED {correct:"0"}]-(s)-[s2:SOLVED {correct:"0"}]->(otherproblem)
WHERE (p.kt = otherproblem.kt) AND (p.id <> otherproblem.id)
RETURN otherproblem.id, otherproblem.difficulty, p.difficulty, count(*) AS strength ORDER BY strength DESC
[:SOLVED] 관계를 정의할 때 해당 relationship의 property로 "correct"를 정의했었습니다. 저는 특정 문항을 "틀린" 사용자 정보를 불러올 것이기 때문에 {correct: "0"} 를 통해 필터링 작업을 추가했습니다.
MATCH (p:Problem {id:"A090024003"})<-[s1:SOLVED {correct:"0"}]-(s)-[s2:SOLVED {correct:"0"}]->(otherproblem)
순서대로, A090024003 ID를 가지는 문항을 틀린 모든 사용자를 불러오고, 해당 사용자가 틀린 또다른 문항들을 불러왔습니다.
WHERE (p.kt = otherproblem.kt) AND (p.id <> otherproblem.id)
이 때, 기준이 되는 문항과 불러온 추천후보 문항들의 학습개념(KnowledgeTag)는 동일하도록 지정했고, 여기서도 당연히 사용자가 아직 풀이하지 않은 문항을 추천해주기 위해 ID가 다른 문항 만을 불러오도록 했습니다.
RETURN otherproblem.id, otherproblem.difficulty, p.difficulty, count(*) AS strength ORDER BY strength DESC
여기서는 count(*) 를 추가해, 각 추천문항(otherproblem) 이 얼마나 많은 노드와 연결되었는 지를 기준으로 정렬하도록 했습니다. 이를 통해 틀린 사용자가 더 많은 문항을 확인할 수 있습니다.
나름대로 학습추천을 위한 기획구상도 해보고, 간단하지만 체계적인 학습 지식그래프를 구축해보았습니다. 표현하고 구현하려 하는 것들을 그래프 구조로 바로 나타낼 수 있다는 것을 이번 포스팅을 통해 직접 경험할 수 있었습니다. 지식그래프 기반의 더 다양한 활용이 궁금해지네요!
'AI' 카테고리의 다른 글
Knowledge Graph
Knowledge Graph(지식 그래프)는 semantic network 라고도 알려져 있으며, 사물, 사건, 상황, 개념 등의 현실세계에서 다루어 지는 다양한 엔티티(Entity)들을 그들 간의 관계성(Relationship)과 함께 표현하는 그래프입니다. Knowledge Graph는 꽤 오래전부터 등장한 개념이지만, 최근 RAG(Retrieval-Augmented Generation) 방식으로 LLM(Large Language Model)을 사용하는 사례가 늘어나면서 지식 베이스 구조화의 중요성이 더욱 증대되고 있습니다. 특히 Graph 기반의 지식 저장 방식은 LLM 성능향상에 도움을 준다고 알려져 있습니다. GraphDB를 활용하면, 정보 간의 복잡한 관계를 구조화할 수 있고 이를 활용해 쿼리의 의도를 이해하고 정확한 정보를 찾기 용이해지기 때문인데요. 아무튼, 저 또한 세상의 흩어진 지식데이터들을 그래프 형태로 구조화하는 것의 중요성을 직접 적용해보기 위해 지식그래프 기반의 추천시스템을 구현해보려 합니다.
Knowledge Graph for Recommender System
Graph 를 활용해 추천시스템은 어떤 식으로 구현될 수 있을까요? 위 그림은 Neo4j Movie Graph DBMS 가이드의 일부입니다. 영화 출연 배우와 감독, 영화 정보들의 관계를 표현한 그래프를 통해 어떤 추천을 할 수 있는 지 예시가 작성되어 있는데요. 기본적인 추천을 위한 접근방식은 인접하는 노드와 연결된 관계를 찾는 것이라 언급되어 있습니다. (A basic recommendation approach is to find connections past an immediate neighborhood that are themselves well connected.) 그래서 첫째로, 톰행크스 배우에게 동료를 추천하기 위해, 함께 촬영한 배우(coActors)와 함께 일한 또 다른 배우(cocoActors)를 찾아 추천해줍니다. 이웃을 찾아 그 이웃과 연결된 또 다른 누군가를 추천하는 것입니다. 둘째로는, 톰행크스와 함께 연기한 배우들 중 톰 크루즈가 출연한 영화에 등장한 적이 있는 배우를 추천합니다. 톰크루즈와 연결될 수 있는 중간다리역할의 배우를 찾기 위해서입니다. 이렇듯 이미 사람과 아이템 간의 관계가 지식그래프로 구조화되어 있기 때문에, 이를 활용한 추천 논리만 정의한다면 Cypher 쿼리문만으로 추천시스템 구현이 가능합니다.
이를 교육에 적용해보려 합니다. 교육, 학습에서는 학생들에게 수준별 문항을 추천하거나, 부족한 개념을 채워줄 학습콘텐츠를 추천해주어야 합니다. 크게 세가지 정도로 정의해보았습니다.
1. 기반 개념 추천
먼저, 개념학습이 필요한 학생에게는 선행학습보다는 기반학습이 중요할 수 있습니다. 위 그림은 고등 수학 상에 등장하는 '이차방정식'이라는 개념을 공부하기 위해서는 연결된 3가지의 기반 개념이 필요하다는 것을 나타낸 그래프라 할 수 있습니다. 보시다시피 중학교3학년에 등장하는 이차방정식에 관한 개념들을 알아야, 고등 수학 상에 등장하는 이차방정식 개념을 해결할 수 있다고 말하고 있네요.
이 경우에는, 만약 학생이 고등 수학-상의 이차방정식을 공부하고 있고 기본적인 문제를 해결하지 못하거나 개념 이해에 어려움을 겪고 있다면, 기반이 되는 중등 3학년 개념을 추천해주어, 복습하도록 유도할 수 있을 것입니다.
2. 문항 추천
다음은 문항추천입니다. 가장 흔히 시험을 대비하기 위해 수준에 맞는 문항을 추천하거나 풀었던 문제와 유사한 문항을 추천할 수 있을 것 같은데요. 위 그림은 노란색으로 표현된 각 개념과 관련한 여러 문제를 표현한 그래프입니다. 만약 학생이 '이차방정식을 푼다' 라는 개념의 문항 10번을 틀렸고, 그럼 이 사용자에게는 같은 개념의 문항을 더 연습해보라고 같은 개념의 다른 문항을 추천해줄 수 있을 것입니다.
3. 문항 추천 (사용자 기반)
다음 추천 방식도 문항추천입니다. 직전의 문항추천과 다른점은 사용자 정보가 추가되었다는 점입니다. 이번에는 개념과 문항 정보 뿐만 아니라, 각 문항을 풀이한 모든 학생들의 정보까지 그래프로 표현해서, A 학생이 만약 문항 10번을 틀렸다면, 문항 10번을 틀린 다른 학생들이 많이 틀린 또 다른 문항인 6번을 A 학생에게 추천해주는 것입니다. 협업필터링과 유사하게, 사용자 행동데이터를 기반으로 유사한 아이템을 추천하겠다는 뜻이고, 여기서 행동데이터가 문항 정오답여부, 아이템이 문항이 된 것입니다. 쉽게 표현하면, "이 문항을 틀린 학생들은 또 이런 문항을 틀렸으니 함께 공부해보세요!" 정도로 정리해서 학생에게 보여줄 수 있겠네요.
위 세가지 정도의 학습 추천 시스템을 구현하기 위해서 우선 개념과 문항, 학생 정보를 표현한 지식그래프를 구축하고, Cypher 를 활용해 추천시스템을 간단히 구현해보려 합니다.
수학분야 학습자 역량 측정 데이터 - AIHub
https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=133
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
aihub.or.kr
제가 사용한 데이터는 AI 허브에 등록되어 있는 수학분야 학습자 역량 측정 데이터 입니다. 이전에 제가 해당 데이터셋에 대해 간단히 리뷰한 적이 있습니다. 참고바랍니다. https://uoahvu.tistory.com/entry/AIEd를-위한-학습풀이이력-공개데이터셋
해당 데이터에서 추천시스템 구현에 사용한 데이터셋은 아래와 같습니다.
1. 문항정오답표
{"learnerID": "A090000914", "learnerProfile": "M;S01;9", "testID": "A090000001", "assessmentItemID": "A090001001", "answerCode": "0", "Timestamp": "2021-05-30 11:56:11"}
학생(learner)별 문항(assessmentItem) 정오답(answerCode) 데이터
2. 문항IRT
{"testID": "A090000072", "assessmentItemID": "A090072006", "difficultyLevel": "0.8390383520999999", "discriminationLevel": "1.3322960958", "guessLevel": "0.0034785868", "Timestamp": "2020-12-24 01:01:46", "knowledgeTag": "2648"}
문항(assessmentItem)별 IRT(문항반응이론) 난이도(difficultyLevel), 변별도(discriminationLevel), 추측도(guessLevel) 데이터
3. 수학지식체계 데이터셋
"0": {
"fromConcept": {
"id": 3249,
"name": "거듭제곱",
"semester": "고등-수1-전체",
"description": "임의의 수 $a$와 양의 정수 $n$에 대하여 $a$를 $n$개 거듭하여 곱한 것을 $a$의 $n$제곱이라 하고 $a^n$으로 나타낸다. 또 $a,a^2,a^3,\\cdots,a^n,\\cdots$을 통틀어 $a$의 거듭제곱이라 한다.",
"chapter": {
"id": "587",
"name": "지수함수와 로그함수 > 지수 > 거듭제곱과 거듭제곱근"
},
"achievement": {
"id": "314",
"name": "거듭제곱과 거듭제곱근의 뜻을 알고, 그 성질을 설명할 수 있다."
}
},
"toConcept": {
"id": 1442,
"name": "거듭제곱",
"semester": "중등-중2-1학기",
"description": "같은 수나 문자를 거듭하여 곱한 것을 간단히 나타낸 것",
"chapter": {
"id": "481",
"name": "식의 계산 > 단항식의 계산 > 지수법칙"
},
"achievement": {
"id": "88",
"name": "지수법칙을 이해한다."
}
}
},
수학 교육과정 간의 지식체계를 나타낸 데이터
기준개념(fromConcept)의 선행개념(toConcept)의 메타정보 데이터
Knowledge Graph 구축하기 (CSV to Neo4j)
학습 추천 시스템 구현을 위해 Knowledge Graph를 구축하기 위해, Neo4j를 활용할 예정입니다. Neo4j는 그래프 데이터베이스 DBMS이며, Cypher라고 하는 그래프 쿼리 언어를 통해 그래프 데이터를 다룰 수 있습니다.
위에서 소개한 수학역량데이터셋은 모두 json 파일의 데이터들이며, 저는 이 json 형태의 데이터셋을 컨셉별로 csv 데이터로 생성했고, 생성한 데이터는 아래와 같습니다.
- concept csv : 개념 데이터
<3. 수학지식체계 데이터셋>에서 추출한 개념 메타정보이며, "toconceptid" 컬럼으로 toConcept 키 데이터를 추가했습니다.
- chapter.csv : 단원 데이터
<3. 수학지식체계 데이터셋>에서 추출한 Chapter 메타정보 ID에 맵핑되는 Chapter name 테이블입니다.
- correct.csv : 정오답 데이터
<1. 문항정오답표> 에서 추출한 학생(learner)별 문항(assessmentItem) 정오답(answerCode)을 나타낸 테이블입니다.
- problem.csv : 문항 데이터
<2. 문항IRT> 데이터에서 추출한 각 문항(assessment)의 IRT 정보가 들어있는 테이블입니다. "knowledgeTag" 컬럼의 아이디정보는 concept.csv 의 id와 맵핑됩니다.
그렇다면, 이 CSV 파일들을 가지고 Knowledge Graph를 구축해보겠습니다. Graph를 구축하기 위한 Cypher 기본 문법은 Cypher 공식 docs를 참고했습니다. :) https://neo4j.com/docs/cypher-manual/current/introduction/
Introduction - Cypher Manual
This section provides an introduction to the Cypher query language.
neo4j.com
1. 개념과 단원 관계 나타내기
먼저, KnowledgTag 혹은 Concept 이라 불리는 학습 개념과, Chapter 즉 단원을 노드로 생성하고, 이 학습개념(Concept)들이 어떤 단원(Chapter)에 속하는 지 표현해보겠습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load Concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept.csv' AS row
MERGE (c:Concept {id: row.id, name: row.name})
RETURN count(c);
// load Chapter nodes
LOAD CSV WITH HEADERS FROM 'file:///chapter.csv' AS row
MERGE (h:Chapter {id: row.chapterid, name: row.chapternm})
RETURN count(h);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///concept.csv' AS row
MATCH (c:Concept {id: row.id})
MATCH (h:Chapter {id: row.chapterid})
MERGE (c)-[:BELONGS_TO]->(h)
RETURN *;
생성해주었던 concept.csv 에서 학습개념(concept)의 id, name을 노드 property로 불러왔습니다. 단원(Chapter) 정보도 함께 표현해줄 것이기 때문에 chapter.csv 에서 chapterid, chapternm을 불러와 노드로 생성해줍니다. 생성된 학습개념과 단원 노드를 연결하는 관계(relationships)는 [BELONGS_TO]라는 이름으로 정의하여, 각 학습개념이 어떤 단원에 속하는 지를 연결해주었습니다.
MATCH (n:Concept)-[r]-(m:Chapter)
RETURN n, r, m
학습개념은 베이지색 노드, 단원은 핑크색 노드로 표현되었고, 각 학습개념이 어떤 단원에 속해있는 지 확인할 수 있습니다. 하나의 단원에는 여러 개념들이 포함되어 있기 때문에 단원의 노드 크기를 크게 하여 포함관계를 시각화했습니다.
확대해 살펴보면 위 그림처럼 어떤 단원에 어떤 학습개념들이 포함되어 있는 지 확인할 수 있습니다.
2. 개념과 개념 간의 선후관계 연결하기
사용했던 데이터셋은 수학지식체계 즉, 개념간의 선후관계가 표현되어 있던 데이터 였습니다. 그래서 학습 개념이 어떤 단원에 속해있는 지 뿐 아니라, 각 학습개념들이 또 어떤 학습개념과 연계되는 지를 알 수 있었는데요. 따라서 concept과 concept 노드 간의 관계를 하나 더 추가해서, 연계되는 학습개념을 확인할 수 있도록 해보겠습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load Concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept.csv' AS row
MERGE (c:Concept {id: row.id, name: row.name, semester: row.semester, description: row.description})
RETURN count(c);
// load Chapter nodes
LOAD CSV WITH HEADERS FROM 'file:///chapter.csv' AS row
MERGE (h:Chapter {id: row.chapterid, name: row.chapternm})
RETURN count(h);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///concept.csv' AS row
MATCH (c:Concept {id: row.id})
MATCH (h:Chapter {id: row.chapterid})
MERGE (c)-[:BELONGS_TO]->(h)
RETURN *;
// create (linkage concept) relationships
LOAD CSV WITH HEADERS FROM 'file:///concept.csv' AS row
MATCH (c:Concept {id: row.id})
MATCH (tc:Concept {id: row.toconceptid})
MERGE (c)-[:BASED_IN]->(tc)
RETURN *;
나머지는 동일하고, 가장 마지막에 concept 사이의 관계를 정의하는 쿼리만 추가되었습니다. [BASED_IN] 이라는 관계를 정의하여, concept.csv에서 id와 toconceptid 컬럼이 연결될 수 있도록 구현했습니다. 이를 통해 기준이 되는 학습개념(c:Concept)이 어떤 학습개념(tc:Concept)과 연계되는 지를 표현했습니다.
MATCH (fc:Concept)-[r1]-(tc:Concept)-[r2]-(m:Chapter)
RETURN fc, r1, tc, r2, m
fromconcept과 toconcept 노드를 연결하고, toconcept이 어떤 단원에 속하는 지 표현해주었습니다. 1번에서는 단원별로 노드들이 동떨어져 있었다면, 이번에는 개념끼리의 연계관계까지 포함되었기 때문에 엣지들이 얽힌 모습을 확인할 수 있습니다.
BASED_IN 관계 엣지가 도착하는 방향에 있는 노드가, 출발한 노드의 기반이 되는 학습개념이라는 뜻입니다.
하나를 확대해서 볼까요? <급수의 발산>이라는 학습 개념은 <발산> 이라는 학습개념에 기반한다고 표현되어 있습니다. 각 노드의 property의 semester 메타를 보면 알다시피, 수2에서 <발산> 개념을 먼저 배운 후에 미적 과목에서 <급수의 발산>을 배우게 됨을 확인할 수 있네요.
3. 문항정보와 학생정보, 정오답 표현하기
이제는 학생 정보까지 추가해보려 합니다. 결국 우리는 문항 추천까지 구현해야 하고, 그러기 위해서는 학생들이 어떤 문항을 맞혔는 지, 각 학습개념에는 어떤 문항들이 존재하는 지를 알아야 합니다. 따라서 이번에는 아까 만들어 주었던 CSV 중 문항 정보가 들어있던 problem.csv 과 학생별 문항 정오답 이력이 들어있던 correct.csv를 사용합니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load students nodes
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MERGE (s:Student {id: row.learnerID, profile: row.learnerProfile})
RETURN count(s);
// load problem nodes
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MERGE (p:Problem {id: row.assessmentItemID, difficulty: row.difficultyLevel, kt: row.knowledgeTag})
RETURN count(p);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MATCH (s:Student {id: row.learnerID})
MATCH (p:Problem {id: row.assessmentItemID})
MERGE (s)-[:SOLVED{correct: row.answerCode}]->(p)
RETURN *;
correct.csv에서 학생 정보를 불러와 Student 노드로 정의했고, problem.csv 에서 문항 정보 중 난이도, 학습개념 정보를 불러와 Problem 노드를 구성했습니다. 그리고 각 학생들이 어떤 문제를 풀었는 지, 그 문제를 맞혔는 지 틀렸는 지를 [SOLVED] 로 표현했고 정오답 여부를 해당 관계 엣지의 property 로 구성했습니다.
MATCH (s:Student)-[c]->(p:Problem)
RETURN s, c, p
LIMIT 100
모든 문항 풀이이력을 불러오면 매우 많아져서, 100쌍의 관계만 출력하도록 LIMIT를 걸었습니다.
초록색으로 표현한 노드는 문항, 파란색 노드는 학생 노드입니다. 4개의 문항에 대해 29명의 학생들이 풀이하였음을 확인할 수 있습니다.
4. 문항정보와 학생정보, 정오답 + 각 문항이 속한 개념 관계 표현하기
그럼 더 나아가, 처음에 개념과 단원 정보를 표현했던 것처럼, 각 문항에 대한 개념, 단원 정보가 들어가면 더더욱 좋을 것 같습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MERGE (c:Concept {id:row.id, name:row.name, incorrectRate:row.answerCode})
RETURN count(c);
// load students nodes
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MERGE (s:Student {id: row.learnerID, profile: row.learnerProfile})
RETURN count(s);
// load problem nodes
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MERGE (p:Problem {id: row.assessmentItemID, difficulty: row.difficultyLevel, kt: row.knowledgeTag})
RETURN count(p);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MATCH (s:Student {id: row.learnerID})
MATCH (p:Problem {id: row.assessmentItemID})
MERGE (s)-[:SOLVED{correct: row.answerCode}]->(p)
RETURN *;
// create relationships(kt)
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MATCH (p:Problem {kt: row.knowledgeTag})
MATCH (c:Concept {id: row.knowledgeTag})
MERGE (p)-[:knowledge]->(c)
RETURN *;
제가 분석에 사용한 문항 풀이이력이 중학교 3학년 학생들의 이력이라, concept.csv을 그대로 사용하지 않고 중학교 3학년에 해당하는 학습개념만 가져와 사용했습니다. 직전과 달라진 점은, knowledge 라는 관계를 추가하여, 각 문항이 어떤 Concept(학습개념)에 해당하는 지를 표현한 관계를 추가해주었습니다. 또한, 개념(Concept) 노드의 property로 incorrectRate 이라는 메타를 추가하였는데요, 사용한 문항풀이이력을 가지고 concept별 오답률을 계산해 추가해주었습니다. 이는 뒤에는 추천 시스템 구현에 활용할 예정입니다!
MATCH (s:Student)-[r]->(p:Problem)-[k]->(c:Concept)
RETURN s, r, p, k, c
LIMIT 100
결과를 출력해보면, 학생, 문항 정보 외에 베이지색 노드로 개념 노드가 추가된 것을 확인할 수 있습니다.
여기까지 하면 기본적인 학습개념과 단원의 정보 표현부터, 학생정보와 정오답 이력까지 Graph로 표현해보았습니다. 이렇게 구축해본 Knowledge Graph를 기반으로 추천시스템을 본격적으로 구현해보려 합니다.
Knowledge Recommender System by Cypher
제가 위에서, 학습 추천에서 가능한 추천 3가지 정도를 구상해보았었습니다. 크게 기반개념추천, 문항추천이 있었는데요. 앞에서 구축한 Knowledge Graph를 기반으로 Cypher 쿼리언어를 사용해 간단히 추천시스템을 구현해보았습니다.
1. A 개념의 기반 개념들 추천하기 (오답률 순 나열, 쉬운것부터)
먼저, 개념공부가 부족한 학생을 위해 약한 학습개념의 기반이 되는 학습개념을 추천해볼 수 있습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load Concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MERGE (c:Concept {id: row.id, name: row.name, incorrectRate:row.answerCode, semester: row.semester, description: row.description})
RETURN count(c);
// load Chapter nodes
LOAD CSV WITH HEADERS FROM 'file:///chapter.csv' AS row
MERGE (h:Chapter {id: row.chapterid, name: row.chapternm})
RETURN count(h);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MATCH (c:Concept {id: row.id})
MATCH (h:Chapter {id: row.chapterid})
MERGE (c)-[:BELONGS_TO]->(h)
RETURN *;
// create (linkage concept) relationships
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MATCH (c:Concept {id: row.id})
MATCH (tc:Concept {id: row.toconceptid})
MERGE (c)-[:BASED_IN]->(tc)
RETURN *;
중학교 3학년에 등장하는 개념(KnowledgeTag) 정보가 들어간 데이터로 구축한 "2. 개념과 개념 간의 선후관계 연결하기"
지식그래프를 불러왔습니다.
MATCH (fromc:Concept {name:"복잡한 이차방정식을 푸는 방법"})-[:BASED_IN]->(tc)
RETURN tc.name, tc.incorrectRate AS i ORDER BY i ASC
"복잡한 이차방정식을 푸는 방법" 이라는 name을 가진 Concept 노드(fromc)와, 해당 노드와 연결(:BASED_IN)되는 기반 학습개념 노드(tc)를 불러오고 기반학습개념의 name와 오답률을 기준으로 정렬해 출력해보았습니다. 그래프 구조로 쉽게 찾은 기반 학습개념과 관련한 콘텐츠를 바로 추천해주거나, 오답률이 낮은 학습개념부터 차근히 추천해볼 수도 있겠네요.
2. A 문항과 같은 개념의 다른 문항 추천
다음은 문항추천입니다. 위에서 문항 추천을 두가지로 나누었었는데, 그 중 같은 개념에 속하는 다른 문항을 추천하겠다는 내용입니다. 만약 어떤 학생이 A라는 개념을 틀렸다면, A 개념에 속하는 또 다른 문제들을 계속 추천해줌으로서 학생이 A개념을 보완할 수 있도록 도울 수 있습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MERGE (c:Concept {id:row.id, name:row.name, incorrectRate:row.answerCode})
RETURN count(c);
// load students nodes
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MERGE (s:Student {id: row.learnerID, profile: row.learnerProfile})
RETURN count(s);
// load problem nodes
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MERGE (p:Problem {id: row.assessmentItemID, difficulty: row.difficultyLevel, kt: row.knowledgeTag})
RETURN count(p);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MATCH (s:Student {id: row.learnerID})
MATCH (p:Problem {id: row.assessmentItemID})
MERGE (s)-[:SOLVED{correct: row.answerCode}]->(p)
RETURN *;
// create relationships(kt)
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MATCH (p:Problem {kt: row.knowledgeTag})
MATCH (c:Concept {id: row.knowledgeTag})
MERGE (p)-[:knowledge]->(c)
RETURN *;
이번에는 문항풀이이력을 기반으로 구축했던 문항, 학생 정보가 포함된 지식그래프를 불러왔습니다.
"인수분해" 라는 name 을 가진 Concept 에 속하는 문항들을 모두 불러온 모습입니다. 총 24개의 문항들이 인수분해 노드와 연결되었네요.
MATCH (p:Problem {id:"A090024003"})-[k]->(c)<-[a]-(otherproblem)
WHERE p <> otherproblem
RETURN otherproblem.id AS 추천문항ID, toFloat(otherproblem.difficulty) AS 추천문항난이도, toFloat(p.difficulty) AS 틀린문항난이도, (ABS(toFloat(otherproblem.difficulty) - toFloat(p.difficulty))) AS 틀린문항과의난이도차 ORDER BY 틀린문항과의난이도차 ASC
MATCH (p:Problem {id:"A090024003"})-[k]->(c)<-[a]-(otherproblem)
"인수분해" 개념에 속하는 문항 중 A090024003 이라는 ID를 가지는 문항을 기준으로 테스트해보았습니다. A090024003 문항(p)이 어떤 개념(c)에 속하는 지(k) 구하고, 해당 개념에 속하는(a) 또 다른 문항(otherproblem)을 불러와줍니다.
WHERE p <> otherproblem
이 때, 추천되는 문항은 사용자가 아직 풀이하지 않은 문항이어야 하므로, 기준이 되는 문항과 동일하지 않도록 WHERE 문을 걸어주었습니다.
(ABS(toFloat(otherproblem.difficulty) - toFloat(p.difficulty))) AS 틀린문항과의난이도차 ORDER BY 틀린문항과의난이도차 ASC
또, 풀이한 문항과 비슷한 난이도의 문항을 추천할 수 있도록 기준 문항과 추천문항 간의 난이도 차이가 적은 순서대로 정렬해 출력하도록 했습니다.
만약, 가장 난이도 차이가 적은 하나만 추천하고 싶다면 LIMIT 1 을 걸어주면 됩니다!
MATCH (p:Problem {id:"A090024003"})-[k]->(c)<-[a]-(otherproblem)
WHERE p <> otherproblem
RETURN otherproblem.id AS 추천문항ID, toFloat(otherproblem.difficulty) AS 추천문항난이도, toFloat(p.difficulty) AS 틀린문항난이도, (ABS(toFloat(otherproblem.difficulty) - toFloat(p.difficulty))) AS 틀린문항과의난이도차 ORDER BY 틀린문항과의난이도차 ASC
LIMIT 1
3. A 문항을 틀린 사용자들이 틀린 문항 추천
다음도 문항추천입니다. 다른 점은 사용자를 기반으로 추천한다는 것이었는데요. 만약 어떤 학생이 A문항을 틀렸다면, A문항을 틀린 다른 사용자들의 정보를 쭉 가져와서, 해당 사용자들이 또 많이 틀린 다른 문항을 추천해주는 것입니다. 다른 학생들이 틀린 문제를 해당 학생은 틀리지 않도록 대비하게 도와줄 수 있습니다.
// clear data
MATCH (n)
DETACH DELETE n;
// load concept nodes
LOAD CSV WITH HEADERS FROM 'file:///concept_m3.csv' AS row
MERGE (c:Concept {id:row.id, name:row.name, incorrectRate:row.answerCode})
RETURN count(c);
// load students nodes
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MERGE (s:Student {id: row.learnerID, profile: row.learnerProfile})
RETURN count(s);
// load problem nodes
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MERGE (p:Problem {id: row.assessmentItemID, difficulty: row.difficultyLevel, kt: row.knowledgeTag})
RETURN count(p);
// create relationships
LOAD CSV WITH HEADERS FROM 'file:///correct.csv' AS row
MATCH (s:Student {id: row.learnerID})
MATCH (p:Problem {id: row.assessmentItemID})
MERGE (s)-[:SOLVED{correct: row.answerCode}]->(p)
RETURN *;
// create relationships(kt)
LOAD CSV WITH HEADERS FROM 'file:///problem.csv' AS row
MATCH (p:Problem {kt: row.knowledgeTag})
MATCH (c:Concept {id: row.knowledgeTag})
MERGE (p)-[:knowledge]->(c)
RETURN *;
방금 사용한 지식그래프와 동일한 그래프를 사용합니다.
다만, 이번에는 A090024003 ID를 가진 문항(Problem) 을 풀이한(s) 사용자 정보(u)를 불러왔습니다.
MATCH (p:Problem {id:"A090024003"})<-[s1:SOLVED {correct:"0"}]-(s)-[s2:SOLVED {correct:"0"}]->(otherproblem)
WHERE (p.kt = otherproblem.kt) AND (p.id <> otherproblem.id)
RETURN otherproblem.id, otherproblem.difficulty, p.difficulty, count(*) AS strength ORDER BY strength DESC
[:SOLVED] 관계를 정의할 때 해당 relationship의 property로 "correct"를 정의했었습니다. 저는 특정 문항을 "틀린" 사용자 정보를 불러올 것이기 때문에 {correct: "0"} 를 통해 필터링 작업을 추가했습니다.
MATCH (p:Problem {id:"A090024003"})<-[s1:SOLVED {correct:"0"}]-(s)-[s2:SOLVED {correct:"0"}]->(otherproblem)
순서대로, A090024003 ID를 가지는 문항을 틀린 모든 사용자를 불러오고, 해당 사용자가 틀린 또다른 문항들을 불러왔습니다.
WHERE (p.kt = otherproblem.kt) AND (p.id <> otherproblem.id)
이 때, 기준이 되는 문항과 불러온 추천후보 문항들의 학습개념(KnowledgeTag)는 동일하도록 지정했고, 여기서도 당연히 사용자가 아직 풀이하지 않은 문항을 추천해주기 위해 ID가 다른 문항 만을 불러오도록 했습니다.
RETURN otherproblem.id, otherproblem.difficulty, p.difficulty, count(*) AS strength ORDER BY strength DESC
여기서는 count(*) 를 추가해, 각 추천문항(otherproblem) 이 얼마나 많은 노드와 연결되었는 지를 기준으로 정렬하도록 했습니다. 이를 통해 틀린 사용자가 더 많은 문항을 확인할 수 있습니다.
나름대로 학습추천을 위한 기획구상도 해보고, 간단하지만 체계적인 학습 지식그래프를 구축해보았습니다. 표현하고 구현하려 하는 것들을 그래프 구조로 바로 나타낼 수 있다는 것을 이번 포스팅을 통해 직접 경험할 수 있었습니다. 지식그래프 기반의 더 다양한 활용이 궁금해지네요!