
Last Query Transformer RNN for knowledge tracing
🚩 https://www.kaggle.com/competitions/riiid-test-answer-prediction
Riiid Answer Correctness Prediction | Kaggle
www.kaggle.com
2020년, 산타토익을 개발한 뤼이드는 Kaggle을 통해 정오답 예측 대회 (Answer Correctness Prediction) 를 개최했습니다. 제가 리뷰한 모델은 본 대회에서 리더보드 1위를 차지한 모델로, Last Query Transformer RNN for knowledge tracing 입니다. 해당 모델의 전체적인 구조를 중심으로, 정오답을 예측하기까지의 과정을 따라가보려 합니다.
📜 https://arxiv.org/abs/2102.05038
Last Query Transformer RNN for knowledge tracing
This paper presents an efficient model to predict a student's answer correctness given his past learning activities. Basically, I use both transformer encoder and RNN to deal with time series input. The novel point of the model is that it only uses the las
arxiv.org
(본 포스팅은 논문의 그림과 표현을 제 방식으로 다시 풀어서 정리한 글입니다.)
1. Model Structure

그림 1은 Last Query Transformer RNN 모델의 전체 구조입니다. 모델의 이름 처럼 Last Query, 마지막 이력만 Query 로 사용하는데요. 이 후 LSTM에는 시퀀스 안에서의 첫번째 이력부터 마지막 이력까지의 입력이 들어가되, 마지막 입력에서는 마지막 Query에 대한 Attention Value 만 더해져 입력되는 형태입니다. LSTM 을 통과해 각 시점에 대한 output이 도출되었다면, 그 중 마지막 이력에 대한 output 만 학습 & 예측에 사용합니다. 이 전반적인 과정을 하나씩 자세히 살펴보겠습니다.
2. Model Input Process
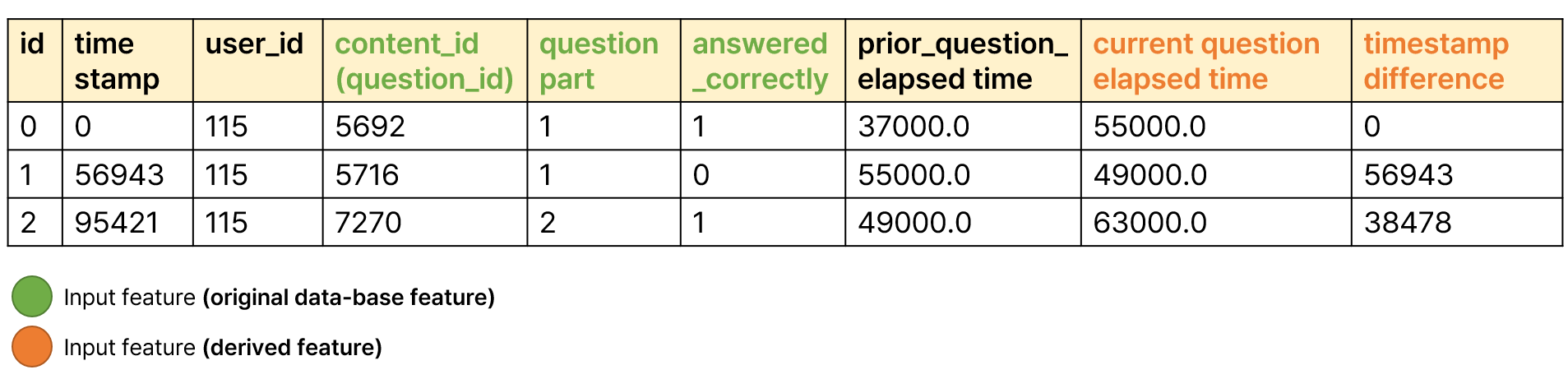
해당 대회에서 뤼이드가 제공하고 있는 데이터의 형태는 위 그림2와 같습니다. 학습자(UserID) 별로 언제(TimeStamp), 어떤 파트(Question Part)에 해당하는 어떤 문제를(QuestionID) 풀이했는지, 그 문제를 맞았는 지 틀렸는지 (Answered Correctly)를 파악할 수 있으며, 그 문제를 풀 때 얼마나 걸렸는 지(Current Question Elapsed Time) 등을 포함하고 있습니다. 시간 순차적 지식추적을 위해서는 기본적으로 학습 단위, 정오답 여부, 타임스탬프가 필요하며, 이 외에 모델의 성능향상 등을 위해 더 더양한 Feature를 사용할 수 있게 됩니다.
논문에서는 총 5개의 Feature를 입력으로 사용했다고 밝히고 있습니다. Question Id, Question Part, Answer Correctness, Current Question Elapsed Time, Timestamp Difference 인데요. Current Question Elapsed Time 은 제공되는 데이터 중 Prior Question Elapsed Time 컬럼을 변환하여 생성, Timestamp Difference는 TimeStamp의 현재row와 이전 row간의 차이를 통해 생성한 것을 알 수 있습니다.

그렇다면 위에서 말한 5개의 Feature를 어떻게 입력으로 사용할 수 있을까요? 그림 3에서 초록색으로 표시한 Feature는 카테고리형 Feature, 주황색으로 표시한 Feature는 연속형 Feature 입니다. 카테고리형과 연속형을 서로 다른 임베딩 레이어를 통과해 임베딩을 진행해주고, 이 임베딩 벡터들을 더해 하나의 Input Vector로 만들어 줍니다. 여러 개의 Feature 들을 하나의 Vector안에 다 담아주는 것입니다. 해당 방법은 논문에서 소개하는 방법으로, 또 다른 방식으로도 접근이 가능할 듯 합니다.

이제 Transformer Encoder, 즉 어텐션 연산을 수행할 차례입니다. 그림4에서 어텐션 연산 과정을 표현했습니다. Query는 논문 제목 처럼 Last Query, 마지막 이력만 쿼리로 사용하게 되는데요. 만약 시퀀스의 길이가 4라면, 4번째의 Query 벡터만 사용하며, Key는 시퀀스 내의 모든 이력을 사용하게 됩니다. 그 결과 마지막 이력에 대한 Attention Score를 구할 수 있게 되며, Attention Score를 구했다면 Value와의 내적을 통해 최종 Attention Value를 도출하게 됩니다. 이는 마지막 이력에 대한 Attention Value에 해당하며, 다시 정리하면 시퀀스 내의 마지막 이력을 Query로 사용하며, 마지막 이력과 시퀀스 내의 이력들과의 연관성을 찾아내는 어텐션 연산을 수행한 것 입니다.

그렇게 마지막 이력에 대한 어텐션 값을 도출했다면, LSTM 모델에 들어갈 차례입니다. 그림 5에서, LSTM 에 어떤 입력들이 들어가게 되는 지를 표현하였는데요. 주황색으로 표시한 것이 그림 4에서 구한 마지막 이력에 대한 Attention Value입니다. 본 모델에서 예측값은 마지막 이력만 사용하지만, LSTM에 입력해주는 것은 시퀀스 내의 모든 이력입니다. 그렇기 때문에 모든 이력에 대한 임베딩 값에, 마지막 이력의 어텐션 값을 더해 LSTM의 Input을 만들어 줍니다. 그림 5의 LSTM Input 에서 주황색과 하늘색을 섞어준 것이 그 이유입니다.
3. Model Output Process

LSTM에 순차적으로 시퀀스 내의 이력들을 Input으로 넣어준 후, output이 나오게 되고, 본 모델에서는 마지막 이력에 대한 예측값만 사용하고 있습니다.
4. With Pytorch Code
👩💻 https://github.com/arshadshk/Last_Query_Transformer_RNN-PyTorch
GitHub - arshadshk/Last_Query_Transformer_RNN-PyTorch: Implementation of the paper "Last Query Transformer RNN for knowledge tra
Implementation of the paper "Last Query Transformer RNN for knowledge tracing" in PyTorch. (Kaggle 1st place solution) - arshadshk/Last_Query_Transformer_RNN-PyTorch
github.com
Last Query Tansformer RNN 모델을 구현한 코드가 깃허브에 존재합니다. 해당 코드를 그대로 가져와, 저는 마지막에 Sigmoid 만 추가해주었는데요. Sigmoid 를 통해 최종 예측값을 0과 1사이의 값으로 출력해 정오답을 예측하는 형태로 만들어주었습니다. 간단한 설명를 주석과 함께 정리한 코드는 아래에서 확인하실 수 있습니다.
🤍 https://colab.research.google.com/drive/1rTh3IBmaOdbCtYO2d5yRw-thA1zPF2e9?usp=sharing
Last Query Transformer RNN for Knoweldge Tracing.ipynb
Colab notebook
colab.research.google.com