
약 6개월전, GraphRAG를 구현하기 위해 Neo4j 그래프 DB를 구축하여, LangChain을 통해 Cypher 쿼리 자동 생성과 질의응답까지의 과정을 업로드 한 적이 있었습니다.
https://uoahvu.tistory.com/entry/GraphRAG-Neo4j-DB와-LangChain-결합을-통한-질의응답-구현하기-Kaggle-CSV-데이터-적용하기
GraphRAG : Neo4j DB와 LangChain 결합을 통한 질의응답 구현하기 (Kaggle CSV 데이터 적용하기)
GraphRAG? 최근 LLM을 잘 활용하기 위해서는 모델이 뱉어내는 텍스트를 그대로 사용하는 것이 아닌, 데이터 베이스를 직접 구축하고 그 데이터를 기반으로 LLM이 답변하도록 구현하는 RAG(Retrieval-Au
uoahvu.tistory.com
오늘은 Langchain이 아닌, Neo4j에서 생성형 AI 를 구현하기 위해 직접 지원하는 파이썬 패키지인 Neo4j GenAI(2024.10.08 ) Neo4j_GraphRAG 로 이름이 변경되었습니다! - 코랩 코드 수정 완료) 를 사용하여 GraphRAG를 구현하고자 합니다. 블로그 글이 아닌 영상으로 더 자세하고 상세한 내용을 함께 확인하고 싶다면 아래 유튜브 영상을 봐주세요! <공원나연> 많관부 🍀
0. GraphRAG 구동방식
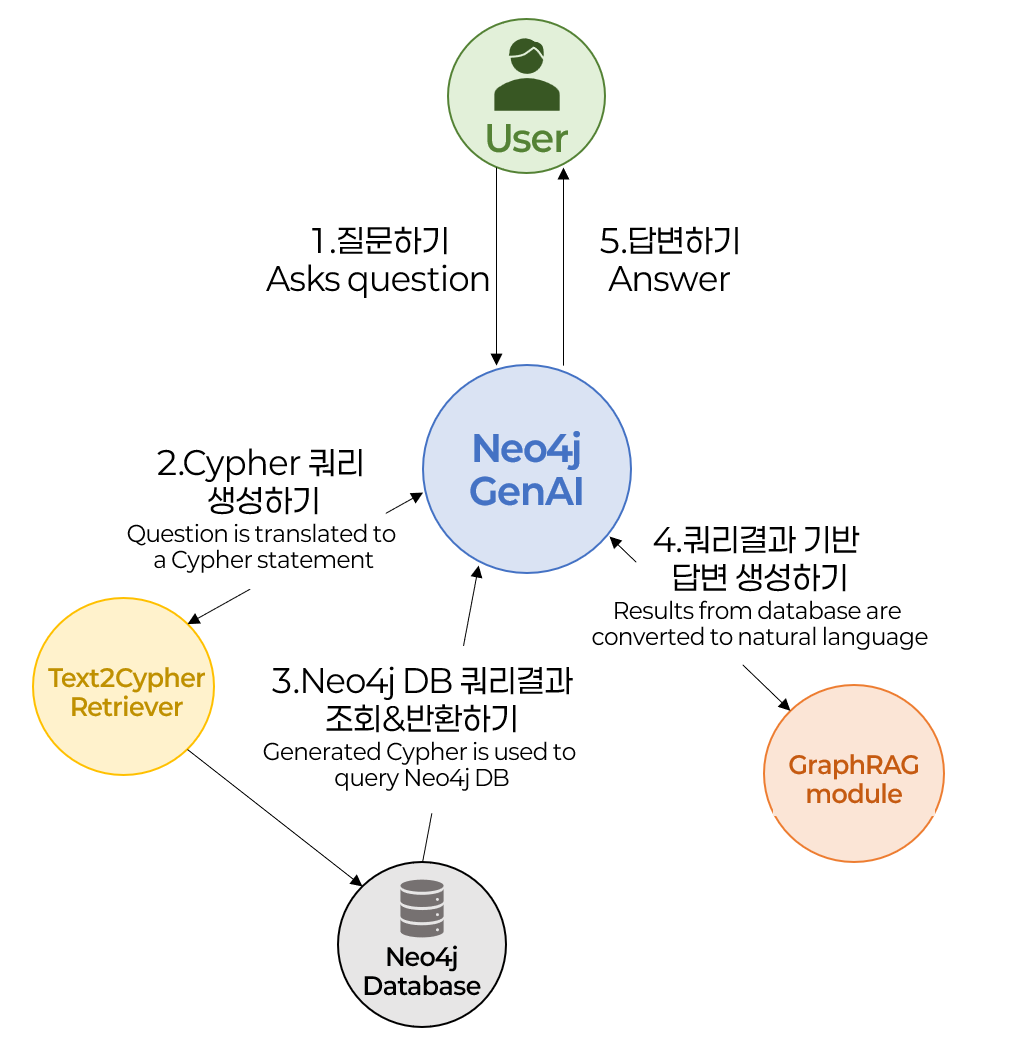
RAG에 대한 개념 설명은 생략하고, (지난 글이나 영상에서 확인할 수 있습니다.) Neo4j GenAI를 활용하여 어떻게 GraphRAG를 구현할 것인 지에 대한 흐름을 먼저 설명드리겠습니다. 그림 1을 함께 봐주세요! 먼저 사용자의 질문이 들어오면, 사용자의 질문에 답변하기 위해 필요한 정보를 얻기 위해 Graph DB를 조회할 수 있는 Cypher 쿼리문을 자동생성합니다.(Text2Cypher Retriever) 쿼리문을 생성할 때도 LLM을 사용하게 되구요! 생성된 쿼리문은 구축되어 있던 Neo4j DB 에 조회 및 검색되어 결과를 반환하게 되고, 검색 결과는 LLM에 참조정보로 전달됩니다. 그리고 최종적으로 LLM은 쿼리 결과 정보를 기반으로 답변을 생성하여 사용자에게 출력하게 됩니다. 이 과정을 이제부터 저와 함께 순서대로 구현해보도록 하겠습니다!
1. GraphDB 구축하기
GraphDB를 구축하기 위해서는 Neo4j Sandbox를 사용할 것입니다. Neo4j Sandbox란 온라인 그래프 데이터베이스로, 무료 클라우드 기반 Neo4j 인스턴스를 구축할 수 있기 때문에 간편하게 리소스를 빌려 그래프 DB를 실험할 수 있습니다.
Home - Neo4j Sandbox
sandbox.neo4j.com
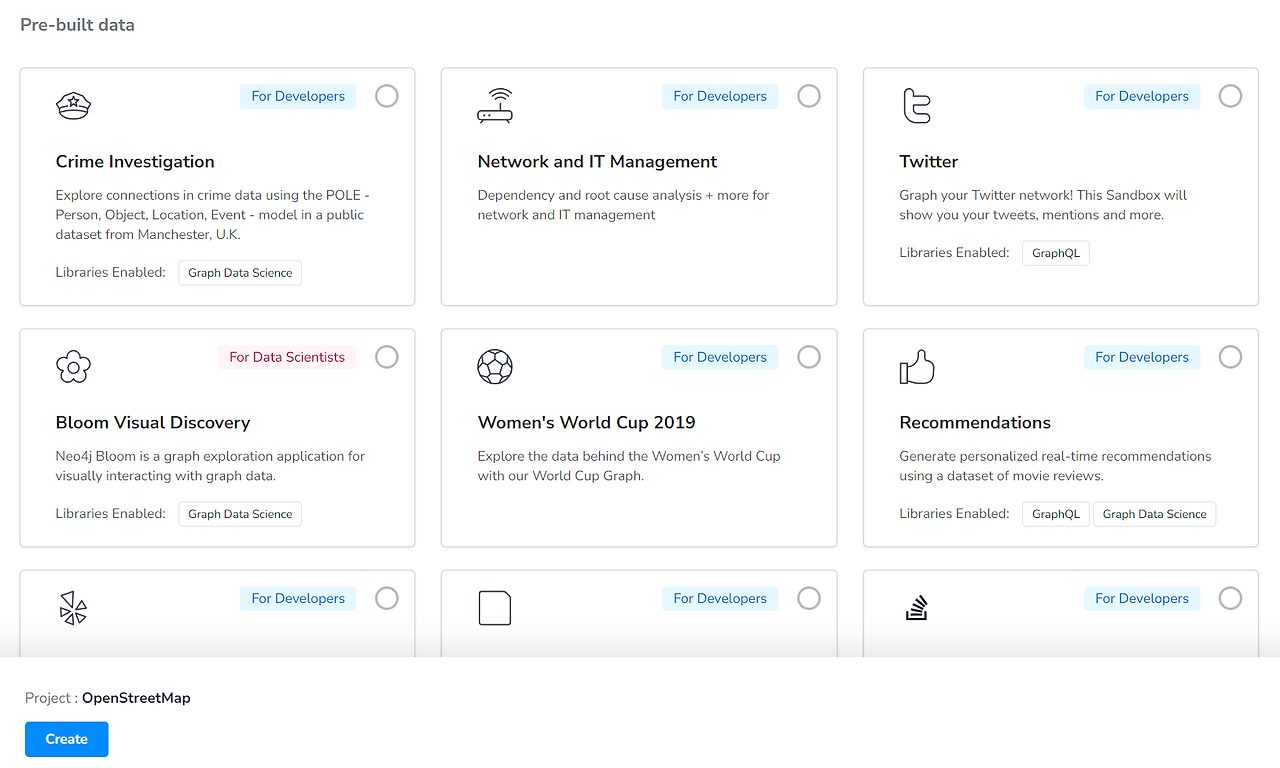
처음 로그인을 하게 되면, 다양한 데이터셋을 직접 선택할 수 있는 화면이 등장하게 되고, 저는 pre-built data 중 영화추천데이터 Recommendations 를 사용하여 진행했습니다.
from neo4j import GraphDatabase, basic_auth
import openai
driver = GraphDatabase.driver(
"neo4j://52.91.251.109:7687",
auth=basic_auth("neo4j", "rest-cast-tackles"))
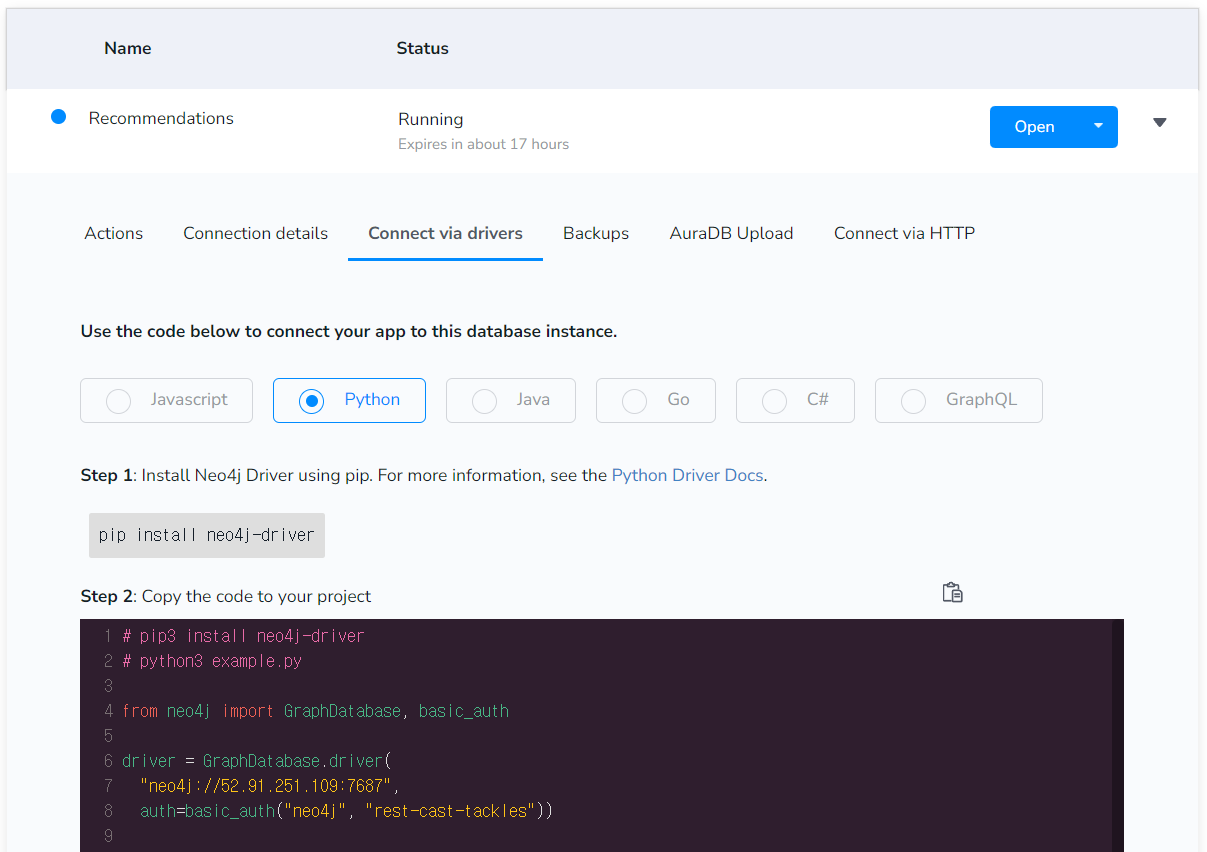
데이터 생성을 하면, driver 를 생성하여 DB와 연결할 수 있는 예제 코드를 확인할 수 있는데, connect via drivers 입니다. 친절하게 파이썬 예제 코드를 제공하고 있으며, 그대로 복붙하여 사용해주면 됩니다!
Driver를 통해 DB가 잘 연동되었는 지를 확인하고 싶다면 아래 코드를 이어서 실행해주시면 됩니다!
cypher_query = '''
MATCH (m:Movie {title:$movie})<-[:RATED]-(u:User)-[:RATED]->(rec:Movie)
RETURN distinct rec.title AS recommendation LIMIT 20
'''
with driver.session(database="neo4j") as session:
results = session.read_transaction(
lambda tx: tx.run(cypher_query,
movie="Crimson Tide").data())
for record in results:
print(record['recommendation'])
#driver.close()
2. DB 정보 검색을 위한 Cypher 자동생성하기
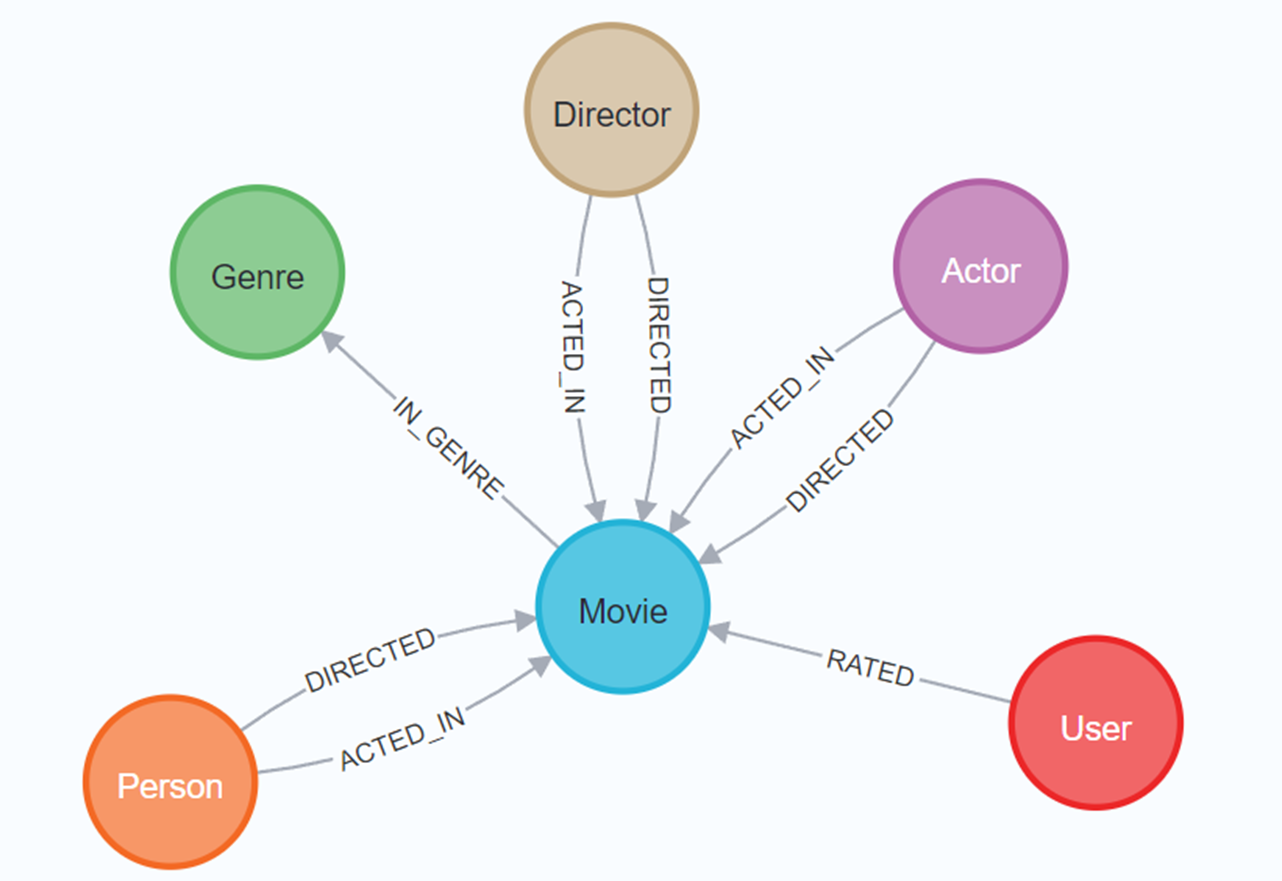
사용자의 질문을 받았다면, 가장 먼저 해야할 것은 질문에 답변하기 위해 필요한 정보를 DB에서 검색해야 하고, 그 검색을 위해 필요한 Cypher 쿼리문을 생성하는 것이었는데요. Recommendations 데이터의 스키마 정보는 위 [그림 4]와 같다는 것을 확인하고 진행해보겠습니다.
질문 : Which actors starred in the Toy Story?
QUERY: MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) WHERE m.title = 'Toy Story' RETURN a.name
만약, 사용자가 토이스토리에 등장한 배우들이 누구인지 물어봤다고 가정해보겠습니다. 생성된 Query 예시를 볼까요? '토이스토리'라는 영화 제목을 가진 Movie 노드에 출연한, 즉 ACTED_IN 이라는 관계를 가지는 Actor 노드를 조회하여, 그 배우의 이름을 반환하도록 쿼리를 생성하였네요.
질문 : What is the average user rating for Toy Story?
QUERY: MATCH (u:User)-[r:RATED]->(m:Movie) WHERE m.title = 'Toy Story' RETURN AVG(r.rating)
하나 더! 이번에는 토이스토리 영화의 사용자 평균 평점을 알고 싶습니다. 그렇다면 먼저 토이스토리 라는 영화에 평점을 매긴 사용자와, 평점 정보를 가져와야 겠죠. 그리고 우리가 필요한 정보는 RATED 관계 속 평점(rating) 정보입니다. 그 중에서도 평균을 물었으니, 생성된 쿼리에서 AVG(rating)을 반환하고 있는 것을 확인할 수 있습니다.
이런 질문 형태는 Vector Retriever 에서는 살아남을 수 없었겠죠.. 이렇게 질문의 의도를 파악하고, 답변에 필요한 정보를 조회하기 위한 Cypher 쿼리를 생성하는 것이 GraphRAG의 핵심이라 할 수 있으며 그 기능을 Neo4j GenAI는 Text2Cypher Retriever를 통해 제공하고 있습니다.
2-1. Text2Cypher Retriever
from neo4j_genai.llm import OpenAILLM
llm = OpenAILLM(model_name="gpt-4o", model_params={"temperature": 0})
Text2Cypher Retriever를 사용하기 위해서는, 결국 그 Cypher 를 생성하는 것도 LLM이 해야할 일이기 때문에 LLM을 먼저 정의해줍니다. neo4j_genai 의 OpenAILLM 을 사용하여 모델을 불러올 수 있으며, 저는 OpenAI의 gpt-4o모델을 사용했습니다.
from neo4j_genai.retrievers import Text2CypherRetriever
retriever = Text2CypherRetriever(
driver=driver,
llm=llm, # type: ignore
neo4j_schema=neo4j_schema,
examples=examples,
)
Text2CypherRetriever 의 사용법은 간단한데요. 4가지 파라미터를 사용했습니다. [1]
- driver(필수) : Neo4j DB 드라이버
- llm(필수) : cypher 쿼리를 생성하는 LLM
- neo4j_schema(선택) : Neo4j DB 스키마 정보 텍스트
- examples(선택) : LLM 이 답변에 참고할 사용자입력/Query 예시 텍스트
driver의 경우 가장 처음에 정의해준 driver 변수를 그대로 사용해주면 되고, llm 은 바로 위에서 불러와줬던 OpenAILLM을 사용하였습니다.
스키마 정보는 공식문서에서 확인해보니 아래와 같은 형태로 입력해줄 수 있었는데요. (그 사이 제가 봤던 공식문서가 사라졌습니다..?) DB에 포함되어 있는 노드와 노드 프로퍼티 및 데이터타입, 관계와 관계 프로퍼티 및 데이터타입을 정리해주어야 했습니다.
Node properties:
Person {name: STRING, born: INTEGER}
Movie {tagline: STRING, title: STRING, released: INTEGER}
Relationship properties:
ACTED_IN {roles: LIST}
REVIEWED {summary: STRING, rating: INTEGER}
The relationships:
(:Person)-[:ACTED_IN]->(:Movie)
(:Person)-[:DIRECTED]->(:Movie)
(:Person)-[:PRODUCED]->(:Movie)
(:Person)-[:WROTE]->(:Movie)
(:Person)-[:FOLLOWS]->(:Person)
(:Person)-[:REVIEWED]->(:Movie)
위와 같은 형식으로 스키마 정보를 작성하여 입력해주기 위해 가공한 코드는 가장 하단의 코랩 코드 안에서 모두 확인할 수 있으니 꼭 확인하시고 스키마를 출력해보시기 바랍니다!
examples = [
"USER INPUT: 'Which actors starred in the Toy Story?' QUERY: MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) WHERE m.title = 'Toy Story' RETURN a.name",
"USER INPUT: 'What is the average user rating for Toy Story?' QUERY: MATCH (u:User)-[r:RATED]->(m:Movie) WHERE m.title = 'Toy Story' RETURN AVG(r.rating)"
]
examples 는 사용자 입력/LLM이 반환하는 Query 에 대한 예시를 작성해 LLM이 참고할 수 있도록 도와주는 것으로, 위와 같이 작성하여 입력해주시면 됩니다. 만약 원하는 방향이 있다면 그것에 맞게 더 다양하게 작성해주면 좋겠죠!
[1] Text2Cypher Retriever : https://neo4j.com/docs/neo4j-genai-python/current/api.html#text2cypherretriever
이 Text2Cypher Retriever를 사용하여 결과를 확인하기 전에, 이 Text2Cypher Retriever가 어떻게 동작하는 것인지, 소스코드를 까서 확인해보고 넘어가겠습니다.
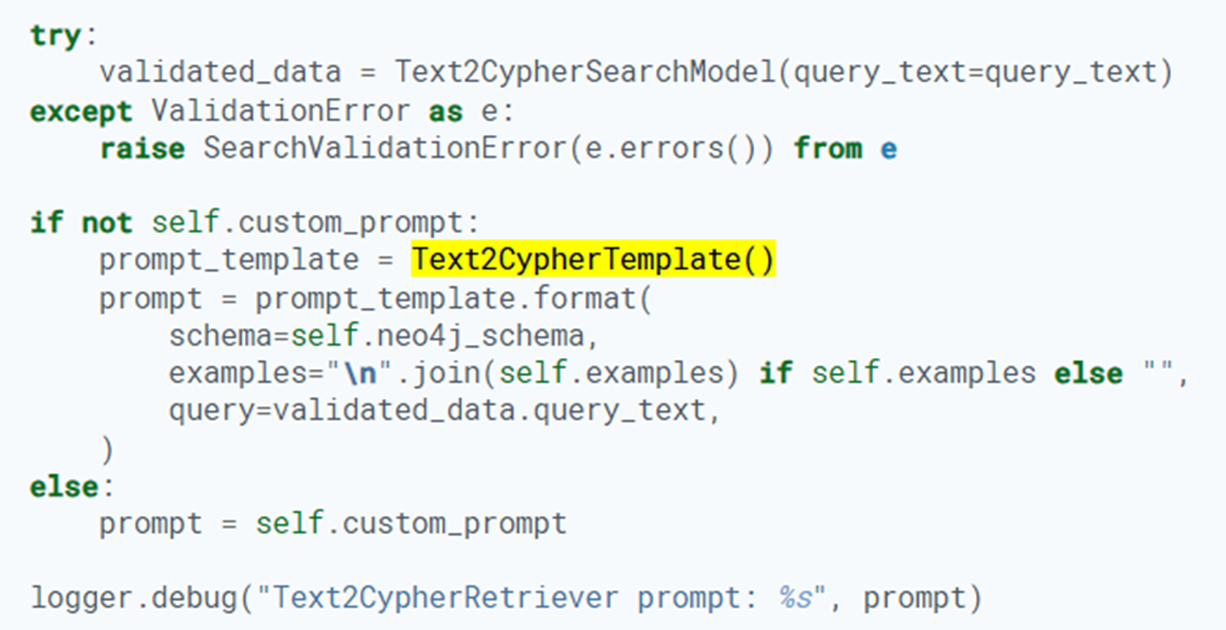
먼저, Text2CypherRetriever 클래스의 소스코드를 내려보니,[2] 사용자가 별도로 파라미터로 입력한 프롬프트 템플릿(custom_promt)이 없다면 Text2CypherTemplate() 을 사용하고 있었는데요. 이 템플릿은 어떻게 작성되어있는 지 확인해보았습니다.
class Text2CypherTemplate(PromptTemplate):
DEFAULT_TEMPLATE = """
Task: Generate a Cypher statement for querying a Neo4j graph database from a user input.
Schema:
{schema}
Examples (optional):
{examples}
Input:
{query}
Do not use any properties or relationships not included in the schema.
Do not include triple backticks ``` or any additional text except the generated Cypher statement in your response.
Cypher query:
"""
EXPECTED_INPUTS = ["schema", "query", "examples"]
def format(self, query: str, schema: str, examples: str) -> str:
return super().format(query=query, schema=schema, examples=examples)
Text2CypherTemplate() 의 템플릿 부분을 확인해보겠습니다. [3] 먼저 LLM의 Task를 "Generate a Cypher statement for querying a Neo4j graph database from a user input. (사용자 입력에서 Neo4j 그래프 데이터베이스를 쿼리하기 위한 Cypher 문을 생성합니다.) 로 정해주고 있습니다. 또한, LLM이 함께 참고할 수 있도록 우리가 파라미터로 넘겨주었던 DB Schema 정보 텍스트, 입력 및 쿼리 결과 예시를 담았던 Examples, 그리고 마지막으로 사용자 질문 텍스트까지 Input으로 넘겨주고 있습니다. 특히 추가로, LLM이 할루시네이션을 포함한 답변을 하는 것을 방지하고, 답변으로 Cypher 쿼리만을 반환할 수 있도록 아래와 같은 프롬프트를 추가해주고 있네요.
Do not use any properties or relationships not included in the schema.
Do not include triple backticks ``` or any additional text except the generated Cypher statement in your response.
스키마에 포함되지 않은 속성이나 관계를 사용하지 마십시오.
응답에 생성된 Cypher 문을 제외한 삼중 백틱 ```이나 추가 텍스트를 포함하지 마세요.
2-2. Cypher 생성 결과 확인하기
그럼 이제 Retriever 조회 결과를 확인해보겠습니다!
query_text = "Which movies did Tom Hanks star in?"
search_result = retriever.search(query_text=query_text)
위에서 생성했던 retriever 객체에 .search 를 붙여 사용할 수 있습니다. 저는 톰행크스가 출연한 영화가 어떤 것인지에 대해 물어보았는데요.

search 후 반환되는 결과에.items 를 붙이면 retriever가 생성한 Cypher 쿼리에 의해 어떤 값들이 조회되었는 지를 확인할 수 있습니다. 뒤에서 나오겠지만 이 값들이 RAG에서 LLM이 참고할 수 있는 정보로 사용됩니다.

추가로, retriever가 생성한 Cypher 쿼리를 확인하고 싶다면, .metadata 메소드의 'cypher' 키를 출력해주면 됩니다! 톰행크스가 출연한 영화를 질문했기 때문에, 배우의 이름이 톰행크스인 Actor 노드와 Movie 노드가 연결되는 관계를 조회하고, 그 영화들의 제목(title)을 반환하도록 생성되었네요! 이렇게 사용자의 질문 만으로 의도를 파악해서 DB조회에 필요한 Cypher 쿼리를 잘 생성해주는 것까지 확인할 수 있었습니다. 이제 이걸로 본격적으로 RAG를 구현해보아야겠습니다.
[2] Text2CypherRetriever source code : https://neo4j.com/docs/neo4j-genai-python/current/_modules/neo4j_genai/retrievers/text2cypher.html#Text2CypherRetriever
[3] Text2CypherTemplate() source code : https://github.com/neo4j/neo4j-genai-python/blob/5c40b03122f7efe87e9a185a9fdd6c6c7524f9a6/src/neo4j_genai/generation/prompts.py#L100
3. Graph RAG 구현하고 결과 확인하기
이제 최종적으로 RAG방식으로 답변을 생성해볼 차례입니다! 혹시 전체적인 과정을 잊으셨다면 [그림 1]에서 4,5번 단계에 해당합니다!
from neo4j_genai.generation import GraphRAG
rag = GraphRAG(retriever=retriever, llm=llm)
GraphRAG 의 사용법은 간단합니다. neo4j_genai 에서는 RAG를 위해 GraphRAG 클래스 또한 제공하고 있는데요. 입력해주어야할 파라미터는 어떤 retriever를 사용할 것인지, 답변생성 시 어떤 LLM을 사용할 것인지 딱 2개만 입력해주면 됩니다. retriever 의 경우 다양한 종류의 retriever를 neo4j_genai에서 제공해주고 있는데요. 이번에는 위에서 알아보았던 Text2CypherRetriever 를 사용해주었고, 만약 더 다양한 검색 방법을 활용하고 싶다면 아래 공식 문서를 참고해주시기 바랍니다.
https://neo4j.com/docs/neo4j-genai-python/current/api.html#retrievers
API Documentation — neo4j-genai-python documentation
neo4j_genai.indexes.create_fulltext_index(driver, name, label, node_properties, neo4j_database=None)[source] This method constructs a Cypher query and executes it to create a new fulltext index in Neo4j. See Cypher manual on creating fulltext indexes. Impo
neo4j.com
RAG 또한 바로 결과를 확인하기 전에, 내부적으로 어떻게 구현되어 있는 지 간단히 소스코드를 보면서 살펴보고 넘어가도록 하겠습니다!

위 코드는 GraphRAG 소스코드 중 일부인데요.[4] 사용하는 프롬프트 템플릿을 확인해보니 RagTemplate() 을 사용하고 있습니다. 그럼 이 템플릿이 어떻게 구현되어 있는 지 확인해보겠습니다.
class RagTemplate(PromptTemplate):
DEFAULT_TEMPLATE =
"""Answer the user question using the following context
Context:
{context}
Examples:
{examples}
Question:
{query_text}
Answer:
"""
EXPECTED_INPUTS = ["context", "query_text", "examples"]
def format(self, query_text: str, context: str, examples: str) -> str:
return super().format(query_text=query_text, context=context, examples=examples)
[5] 먼저 LLM에게 Answer the user question using the following context (다음 컨텍스트를 사용하여 사용자 질문에 답하세요.) 라는 명령과 함께 크게 3가지를 정보를 제공하고 있습니다. 첫번째로 LLM이 답변에 참고할 수 있는 DB 정보인 context, 두번째로 LLM이 어떤식으로 답변해줘야 하는 지에 대한 예시를 적은 Examples, 마지막으로 사용자의 질문 텍스트를 넘겨주면 RAG 방식의 프롬프트가 완성됩니다.

그럼 여기서 Context는 어떻게 작성할 수 있을까요? [6] 저희는 Text2CypherRetriever를 사용하여 필요한 정보를 얻고 있습니다. 위 그림은 RAG가 context 텍스트를 어떻게 얻어오고 있는 지를 알 수 있는 소스코드 입니다. context는 retriever_result.items 의 결과값을 join한 텍스트들인 것을 알 수 있는데요. 여기서 retriever_result.items는 retriever의 결과값인 .search의 반환값이며, 이는 그림 0 에서 확인할 수 있었습니다. 즉, Retriever가 생성한 Cypher 쿼리를 통해 얻은 DB 검색 결과들을 묶어 context로 정의하고, 이를 LLM에 함께 넘겨 DB정보를 참조해 답변하도록 만드는 것입니다.
RAG 내부 동작 방식까지 살펴보았으니 이제 사용할 일만 남았습니다!
# 질문하기
query_text = "Which movies did Tom Hanks star in?"
search_result = retriever.search(query_text=query_text)
print("==== [Text2Cypher 를 통해 자동생성한 Cypher] ====")
print(search_result.metadata['cypher'])
response = rag.search(query_text=query_text)
print("\n==== [생성된 Cypher를 기반으로 최종답변생성] ====")
print(response.answer)
Retriever 사용방식과 동일하게 .search 메소드를 사용해주시면 되는데요. 파라미터로는 사용자 질문 텍스트만 입력해주면 끝입니다. 저는 사용자 질문에 의해 retriever가 어떤 Cypher 쿼리를 자동생성 해냈는 지도 확인하고 싶어서 함께 출력해보았습니다.

톰행크스가 출연한 영화가 무엇인 지 질문했었고, 이에 Retriever 가 생성한 쿼리를 보니 톰행크스 라는 이름을 가진 영화배우와 연결되는 Movie 노드를 찾고, 이 영화들의 제목을 조회하도록 생성되었습니다. 그 결과들은 아마 내부에서 context로 전달이 되었을 것이고, 그 결과 "톰행크스가 출연한 영화는 아래와 같습니다." 라는 문구와 함께 DB에서 조회한 영화 제목들을 나열해주며 답변이 생성되는 것을 확인할 수 있습니다.
이 결과를 보니, 확실히 ChatGPT가 방대한 정보들을 기반으로 화려하게 답변해주는 것과는 달리, DB에서 조회된 내용을 기반으로만 정직하게 답변해주고 있습니다. 할루시네이션 현상을 확실히 방지할 수 있으므로 사용자가 미리 정의한 DB내에서 최대한 구조화되고 정확한 지식으로 답변하는 것이 필요하다면 GraphRAG는 매우 유용해보입니다. 특히, 벡터 유사도 검색으로는 질문과 비슷한 문장만 찾아낼 수 있었다면, Text2Cypher 검색을 통한 GraphRAG방식은 질문의 형태가 복잡하더라도 그 속에서 질문의 의도를 파악하기 때문에, 답변에 필요한 정확한 지식을 찾을 수 있는 것입니다. 👏
[4] graphrag.py source code : https://github.com/neo4j/neo4j-genai-python/blob/5c40b03122f7efe87e9a185a9fdd6c6c7524f9a6/src/neo4j_genai/generation/graphrag.py
[5] RagTemplate() source code : https://github.com/neo4j/neo4j-genai-python/blob/5c40b03122f7efe87e9a185a9fdd6c6c7524f9a6/src/neo4j_genai/generation/prompts.py#L80
[6] Context in GraphRAG : https://github.com/neo4j/neo4j-genai-python/blob/5c40b03122f7efe87e9a185a9fdd6c6c7524f9a6/src/neo4j_genai/generation/graphrag.py#L108
더 다양한 예시와 설명이 필요하다면, 아래 코랩코드와 영상들을 꼭 함께 확인 해주세요! 만약 Neo4j_genAI 패키지를 통해 벡터 유사도 검색 기반 검색 엔진부터 구축해보고 싶으시다면 아래 영상부터 확인하시면 좋습니다 😊
그리고 이번 글에서 진행한 모든 코드는 아래 코랩에서 확인할 수 있습니다! ( * 추가 : 2024.10.8 ) neo4j_genai 패키지가 neo4j_graphrag 라는 이름으로 바뀌어 패키지명을 수정하였습니다. )
https://colab.research.google.com/drive/1xBl8jf99-DALsvy0Ir2nHGwVP59QLs8W?usp=sharing
Neo4j GenAI로 Retriever기반 GraphRAG 구현하기.ipynb
Colab notebook
colab.research.google.com